Serverless

Understanding Total Cost of Ownership of Serverless and Container Applications
Last week I published an article discussing when serverless is more expensive than containers. In that post, I did a simple comparison between Lambda, EC2, and App Runner to show relative compute costs.
I also mentioned something a few times in that article that I realized probably needs to be clarified a bit. I qualified my findings by stating that even though we found a tipping point where serverless is more expensive than provisioned resources, the total cost of ownership (TCO) is still lower.
Total cost of ownership is probably not a new concept to many of you reading this post, but in case it is, I want to discuss it and talk about specifics when we compare serverless and serverful applications.
When we talk about a company’s cost to successfully run an application in production, we must consider more than our monthly AWS bill. Everything that goes into the operation of that app factors into the cost.
Contributors to total cost of ownership:
- Infrastructure - Compute, provisioned components, storage
- Initial development - Time from ideation to production
- Maintenance - Patching, OS updates, bug fixes, etc…
This is not an exhaustive list, but it does represent the three major sources of cost for production applications.
Infrastructure Costs
Also known as cost to run, this is what my post last week focused on. Comparing serverless apps with traditional cloud apps in this manner is a bit like comparing apples and oranges, but the end result is your monthly bill.
Serverless infrastructure costs are based on your usage while traditional workloads are based on provisioned resources. These are highly variable costs based on the amount of monthly requests, average request/response sizes, and peak vs sustained load times.
Infrastructure costs are billed monthly and will recur for the life of your application. As you make enhancements to your app the costs may go up or down, but you will always have some sort of infrastructure bill.
Development Costs
These are the upfront cost to build charges that begin to get harder to quantify. To determine development costs, you need to factor in how many developers will be on the project, how much each one of them is paid, and how long it will take.
I’m sure not everyone will agree but speaking generally, serverless development is faster than traditional development.
Why?
Well for one, infrastructure scaling is taken out of the question. Outside of planning for magnitudes of scale, serverless handles it for you. Counter that with designing a system that can elastically scale up and down without too much over provisioning to minimize lost opportunity costs or under provisioning and making your customers unhappy. Determining how to handle production traffic takes careful time and planning in addition to building the software itself.
If you imagine a full time employee costs the company $100K / year, factoring in an additional few weeks of development per developer starts to add up quickly. If serverless knocked 6 weeks of development time off the initial build with a team of 6 engineers, you’re looking at a $70K difference in cost to build.
Maintenance Costs
After the initial development is complete and your application is live in production (congratulations!), you enter the maintenance cycle or cost to support phase.
This is an ongoing personnel charge for the amount of time it takes to keep your application running smoothly. Verifying your application is scaling appropriately, monitoring dashboards and dead letter queues, and new feature addition all fall under this phase.
Some organizations split responsibilities across different teams in this phase. Development teams build new features and tooling, while Site Reliability Engineering (SRE) teams take over management tasks like monitoring dashboards and responding to events.
However, personnel costs are personnel costs. The company is still paying for engineer time in the ongoing maintenance and monitoring, so it’s a cost that must be factored in TCO.
Serverless apps have dead letter queue monitoring and alerts when usage gets close to service limits. But because of the shared responsibility model with serverless, the cloud vendor takes on server software, networking infrastructure, hardware maintenance, and more so you don’t have to.
Contrast that with traditional workloads where server software like OS updates and patching, network configuration, and managing virtual machines is put back on you. You pay not only for the resources you’ve provisioned but for the maintenance efforts of them as well.
Maintenance costs also include productivity losses. When engineers are busy configuring fleets of servers or troubleshooting an issue on a virtual machine, they aren’t given the opportunity to build new features or innovate. This impacts the company in the long term as it pushes out development schedules.
A Real-World Example
I worked on an application for a few years that was completely serverless. This application had an integration requirement to communicate with a piece of legacy software hosted on a load balanced fleet of EC2 instances.
To facilitate the communication, we built a middle tier that would respond to events via webhooks, do some data transformations, then call the legacy system APIs.
This middle tier ran on a separate fleet of EC2 instances, resulting in an architecture resembling below.
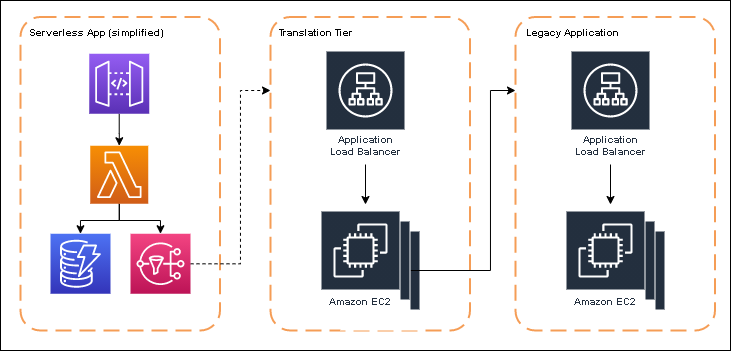
Intentionally simplified architecture diagram
As our go live date approached, we ran our first set of load tests and quickly found out the serverless application rapidly out-scaled our middle tier. The amount of incoming events to the integration webhooks overwhelmed the system and prevented the downstream integrations from running.
So we regrouped, spent a considerable amount of time planning and forecasting traffic loads and peaks, and resized the integration tier. We also put an API Gateway and SQS queue in front of it to act as a buffering mechanism. The EC2 instances would then query the queue and pop items off at its own pace.
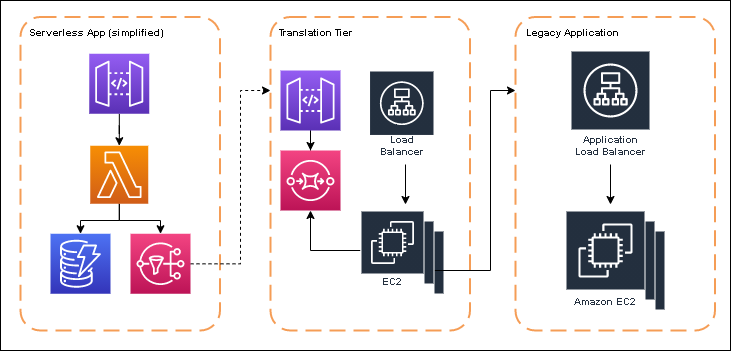
Revised architecture after a load test
After another load test, it seems like we right-sized the environment and were ready for go-live. Hooray!
The day we went live, there were approximately 50,000 users in the system. The serverless application scaled gracefully and handled the surge of traffic without issue. The integration tier was able to handle the traffic as well, but began building a slight backlog of work. The SQS queue with the to-be-done work was starting to enqueue items for longer and longer periods of time.
So our SRE team responded and both horizontally and vertically scaled the EC2 instances in the fleet. In return, the backlog went down and things continued to operate as we expected.
Over the next few months, an eye-opening pattern began to emerge.
The serverless application we built performed like a well-oiled machine. There were some defects found in the software, but the infrastructure had no issues. It scaled up during peak hours and scaled down when during off-peak. Overall, the dev team responsible for that application was able to continue enhancing the application with little to no interruption.
However, the integration tier and legacy application were a different story. We had a team of 7 engineers working around the clock monitoring these applications. They monitored CPU usage, memory allocation, and error queues constantly for the first several weeks trying to stabilize the environment. The bursty nature of our app would cause surges that would overwhelm our initial configuration of this fleet of EC2 instances.
For the first couple of months, nothing but damage control was done on these two apps. There was so much work to do with updating patches, rebooting servers, reconfiguring load balancers, and monitoring server stats that it was impossible to do anything else.
It was quite the contrast to the serverless app.
Summary
In my example, the serverless app cost less money to run, build, and maintain, but it’s not always that way. There will be times when your infrastructure costs for serverless are higher, but you need to take into consideration how much personnel time is going into making the “cheaper” solution run.
Productivity losses, slower rates of innovation, and burnout are all non-tangible aspects of TCO that drive a huge impact on an organization. Serverless development enables engineers to move quicker, not worry about right-sizing their application (to a degree), and save the company some serious money.
Serverless is not a silver bullet, it does take organizational maturity to handle a cloud-native application in production. Upskilling not only your developers, but your support team as well is crucial to your success with this technology.
When questioned about serverless costs “at scale”, be sure to talk about not only the infrastructure costs, but the additional costs to the company like cost to build and cost to support. All these factors drive the success (and profit margins!) of your application.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.