Serverless

Three Ways to Retry Failures In Your Serverless Application
A few years ago when I got into serverless development and event driven architectures, there was so much of mystique and wonder. I didn’t know the purpose of an event bus, I couldn’t wrap my head around asynchronous processes, and I sure couldn’t figure out why you’d need to build retry functionality in an application.
Coming from a strictly synchronous background, retries made no sense. If something didn’t work, just click the button again. While this might be true for a synchronous API call, it is not the case in many serverless environments.
Serverless makes heavy use of events, which are asynchronous in nature. This means the caller does not wait to hear a response before returning. This is a highly effective approach when designing loosely-coupled systems that automatically scale under load. Not to mention it saves you some serious money when Lambda functions don’t have to wait for a process to finish.
When something goes wrong in an asynchronous process, you don’t want it to fail and be lost forever. It’s possible the process failed because of a transient error like a network failure or throttling event. These types of events can safely be retried and expected to go through (assuming the network issues cleared up or you’re under your rate limit).
If your app threw its hands up and said “I quit”, then you’d have needless data loss. We don’t want that.
This is so important in serverless applications that AWS includes it explicitly in the reliability pillar of the serverless application lens of the Well-Architected Framework.
Today we’re going to discuss three levels of retry-ability you can add to your app and the pros and cons of each.
Low-level Retries
AWS already handles a variety of failures for you when you invoke functions indirectly. It addresses the different invocation types with different types of retries.
However, when you are running synchronous invocations you’re on your own.
Lambda Functions
I’m sure we can all agree that most Lambda functions make at least one call to the AWS SDK (but hopefully not more than two). The SDK will automatically retry failures for you, but if you want to take matters into your own hands, you can configure the number of times it retries and how it backs off.
When retrying a failure, it’s standard practice to exponentially backoff with each retry using jitter. Jitter is a random delay used to prevent successive collisions if multiple executions are failing at the same time.
If you use the JavaScript SDK, you can configure retries for each client you instantiate in your functions.
const { DynamoDBClient, PutItemCommand } = require('@aws-sdk/client-dynamodb');
const ddb = new DynamoDBClient({ maxAttempts: 5 });
When the client runs into an issue, it will retry the command up to 5 times before throwing the exception in your function code. If you do not set this value explicitly, the SDK will retry up to three times.
In the event that your function still errors after the max number of attempts, it is highly recommended to drop the event in a dead letter queue (DLQ) for mid-level retries.
Step Functions
If you’re a Step Functions user, you’re in luck. When it comes to retries, this service has you covered. You have the ability to catch, backoff, and retry every state individually.
Contrary to the AWS SDK, this does not happen automatically. You must configure it manually. Luckily, it’s an easy configuration and is even supported in the Workflow Studio.
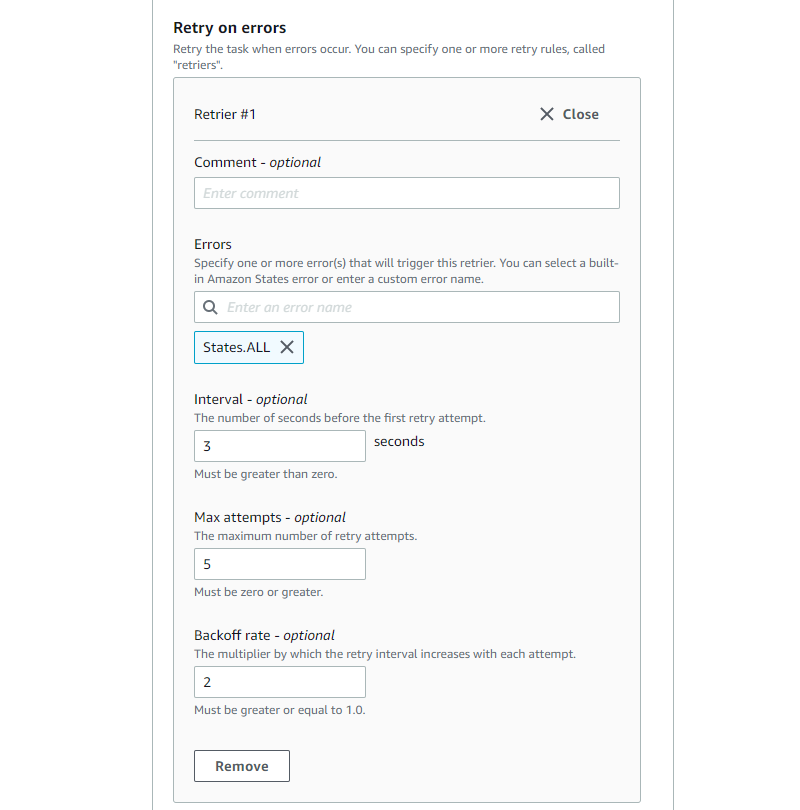
Step Functions Workflow Studio Retry Configuration
Or if you prefer to see the ASL (Amazon States Language):
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 2,
"IntervalSeconds": 3,
"MaxAttempts": 5
}
]
In the scenario where you have maxed out all your retries, you will again want to drop the event or input execution in a dead letter queue. Dead letter queues will store the input and allow you to retry via a mid- or high-level mechanism, or enable you to react manually.
Pros - The primary benefit of a low-level retry is that it feels seamless. You don’t have to provision extra infrastructure to handle errors and the execution does not indicate issues occurred. They are handled for you and on their merry way.
Cons - Depending on how you configure your backoff rates, this method could rack up a large compute bill. If a Lambda function is waiting for an exponential backoff to complete, you will be billed for that run time while it waits.
Mid-level Retries
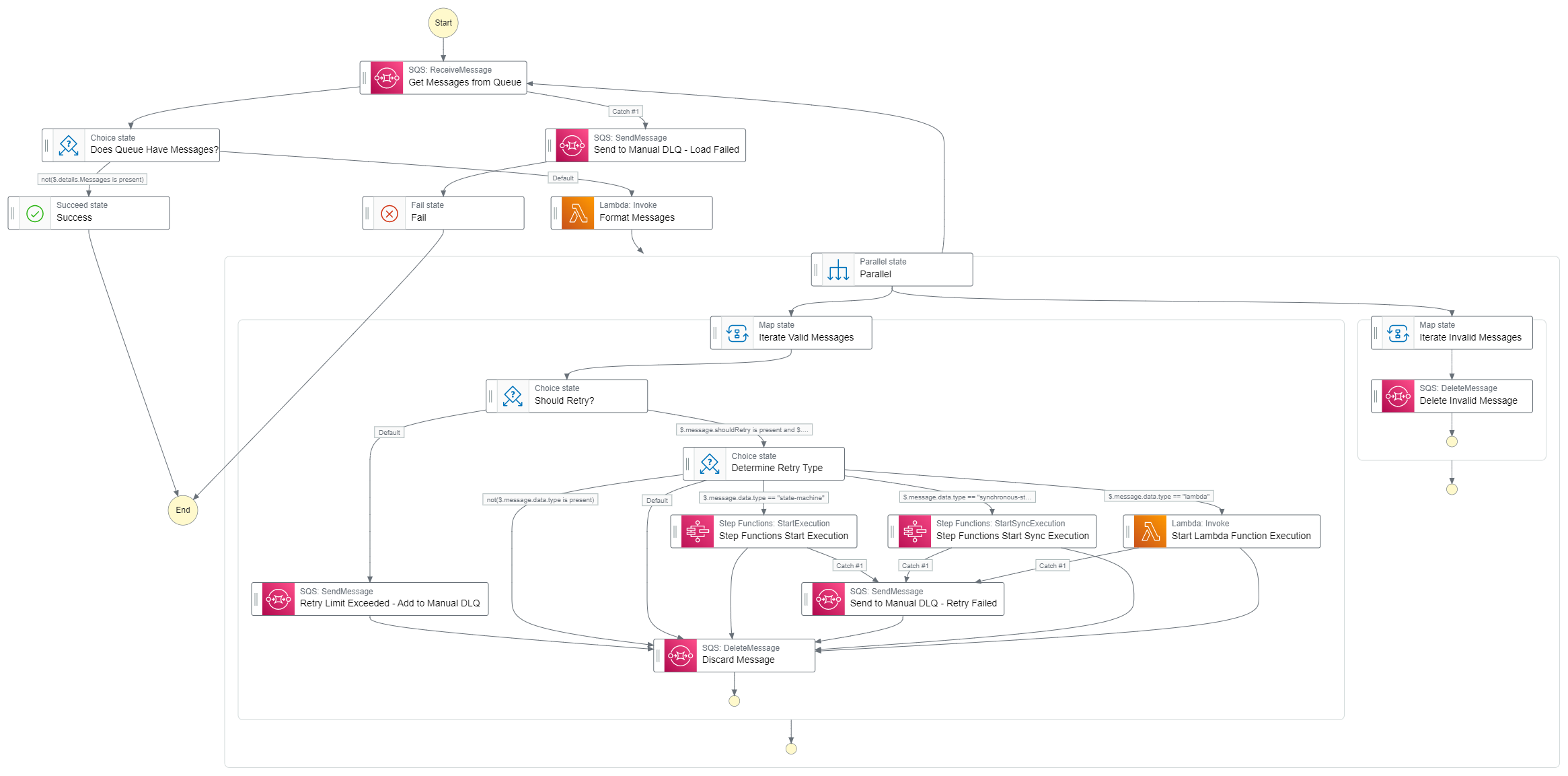
Each level we ascend in our retry ladder adds a level of abstraction. Mid-level retries involve retrying events that live in a dead letter queue. These retries to not operate at the code level of a function, like our low-level retries. Instead, they are specific to a function or state machine and a specific dead letter queue.
Mid-level retry mechanisms can be Lambda functions or state machines that do the following:
- Pop items off the dead letter queue
- Assess if the event can be retried or needs manual intervention
- Perform any transformations or validations
- Resubmit the event back to the function or state machine that added it to the DLQ
This type of retry is aware specifically of the function or state machine that drops items into a DLQ. It provides one-to-one error handling to the compute resource. This means for every Lambda function or state machine you have a dead letter queue and an error management function.
It also implies you have focused, narrowly scoped resources that will handle errors as they occur.
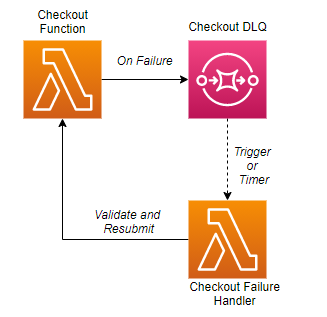
Simple mid-level retry data flow
Pros - The retry functions have minimum privileges. They should be able to read and delete messages from a single queue and invoke a single state machine or Lambda function. You can also make intelligent decisions or transform data in the retrier specific to the failed Lambda function/state machine.
Cons - There are considerably more resources to keep track of and maintain. If you’re not careful you might get yourself into an infinite loop with the retry logic if you don’t keep track of attempts.
High-level Retries
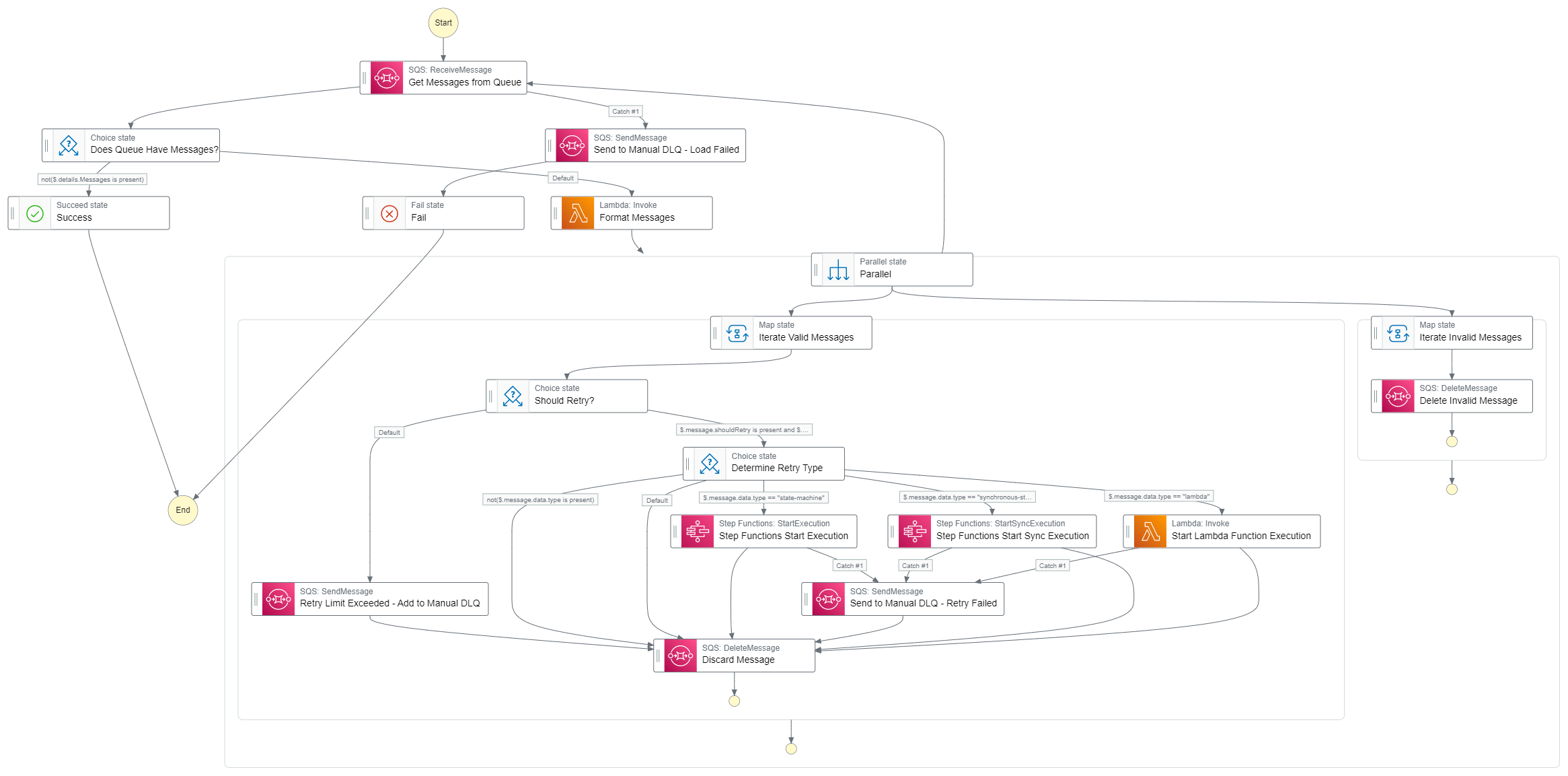
Abstracting the retry process even higher brings us to generic, high-level retries. These mechanisms do not specifically know which state machine or Lambda function it is retrying. Rather, it accepts a structured input from a dead letter queue and resubmits the input without performing any transforms or business logic.
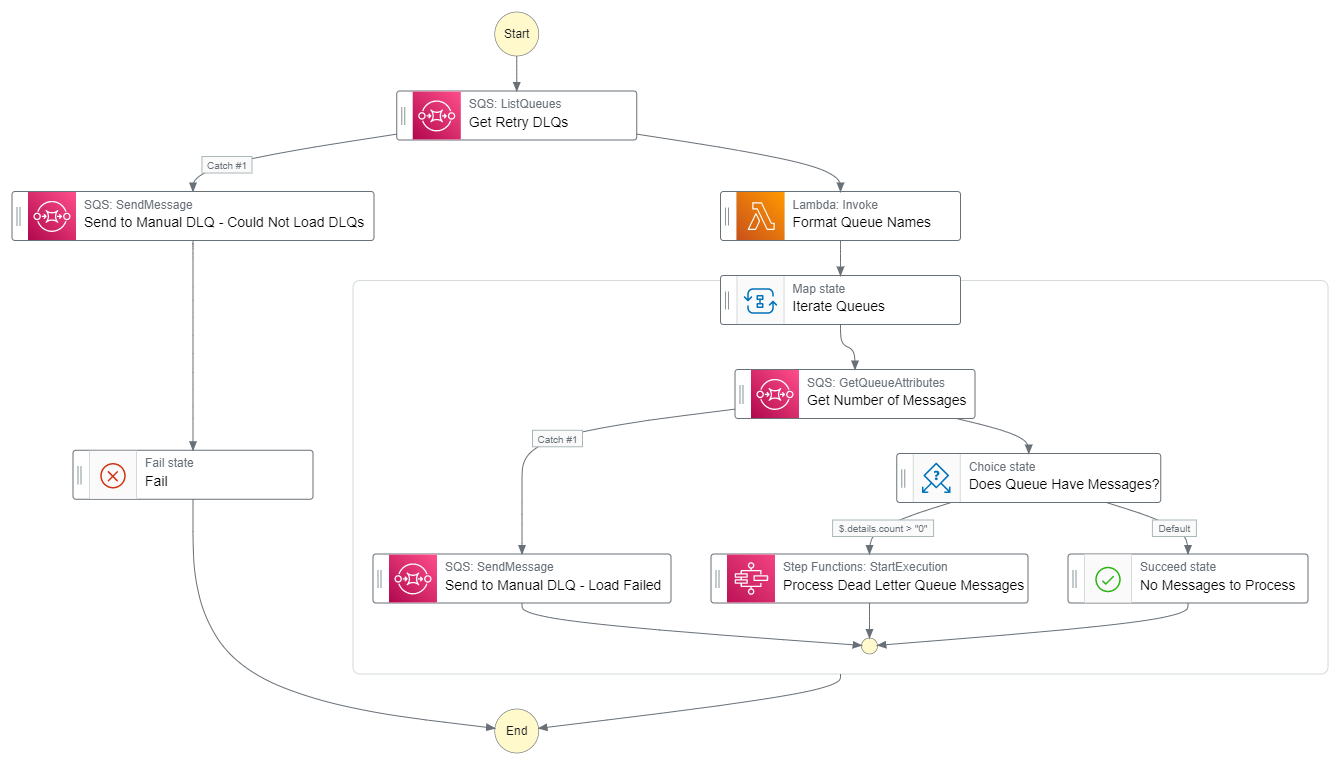
A generic, high-level retry mechanism could be a state machine or set of state machines that look across all dead letter queues in an account, verify if there are messages to be retried, and processes them. In the example below, the state machine is triggered on a 30 minute timer by an event bridge rule.
Dead letter queues are expected to start with the same prefix, i.e. retry-, to be properly identified and separated from queues that serve other purposes.
High-level retry state machine
When the state machine is processing the individual messages, it must determine the type of resource it will be invoking and how many times it has already retried. Ideally these pieces of information would come in from the structured message that was passed into the dead letter queue originally.
Retrying message generically from a dead letter queue
Pros - As your application grows, this approach will automatically pick up and retry errors as they get dropped into DLQs (as long as you name your DLQs and structure your messages appropriately). Your resource count will stay lower because you don’t have specific Lambda function error handlers to pick up items. It also forces a level of governance in the way of structured DLQ logging. Having consistent messaging is great for troubleshooting errors.
Cons - This state machine needs wildcard access to SQS queues, Lambda functions, and state machines. Now, it doesn’t need full admin, but it does need to read and delete messages and invoke state machines and functions. This does not follow the principle of least privilege and opens doors wider than they should be. You also don’t get the benefit of adding business logic and transformations upon retry. Lastly, you could get yourself into an infinite loop here as well if you have a bug in your max attempt logic.
A Word on Idempotency
When dealing with distributed systems, you cannot guarantee exactly-once delivery. You also can’t guarantee that your retry mechanism is going to run on a pristine entity, meaning the operation could have partially succeeded the first time.
Idempotency refers to the ability of an application to run the same API call or function multiple times and it have the same effect on the system. So if I retry the same POST 3 times, it would result in a single entity being created instead of three.
This is not handled out-of-the-box for you. It’s something you need to take on yourself, especially as you start implementing retry logic on your own.
Idempotency patterns are clearly defined and established. If you’re a python user, it’s even included in the python Lambda powertools, which quickly enable your functions to be retry-able.
Retries and idempotency go hand in hand and are part of the aws serverless design principles. While you can do one without the other, you shouldn’t.
For more information on idempotency, check out this blog post.
Conclusion
When operating at any scale, having the ability to retry errors will save you a significant amount of developer time. They won’t be spending their time digging into logs or getting into root cause analysis unnecessarily. If an issue could be resolved by “turning it off and back on again”, then your serverless application will do that for you.
If you had 5,000 transactions in your application every day and an average of 1% failure rate, you’d have 50 failures. If 80% of those were due to transient issues, that means you’d automatically be resolving 40 problems every day. Imagine how happy the engineering and support teams would be if they didn’t have look at those on a regular basis.
You have multiple levels of abstractions for retry. Low-level retries work with errors at the code level. Mid-level retries deal with function or state machine dead letter queues. High-level retries work with everything generically.
My recommendation is to stick with low- and mid-level retries for production software.
The risk you take with the wide open permissions of high-level retry is too high. Serverless is about narrowly scoping permissions. Having a state machine that can read and delete messages from any queue or invoke any function or state machine is just asking for trouble.
If you’re already using the AWS SDK in your Lambda functions, you’re already doing low-level retries. If you’re using Step Functions, make sure to include the retry logic at every state.
Mid-level retries are incredibly effective. They can look downstream or verify data integrity before resubmitting. Get into the habit of including a handler to process and identify errors in your async workflows.
A self-healing application will save you time and money. Automate what you can. It eliminates human error and resolves issues as fast as possible.
Happy coding!


{kind=link}
{kind=link}
Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.