
Serverless

3 Things to Know Before Building a Multi-Tenant Serverless App
A few years ago I was given the privilege to take a team of engineers and “go figure out how to build in the cloud.” There were (mostly) no guidelines, just a vague idea on what kind app we were supposed to build. Sounds like a developer’s dream, right?
It was.
But figuring out how to build in the cloud is a significantly more daunting task than it sounds when approached from an enterprise perspective. We had to figure out what the cloud even was, what on Earth CI/CD is all about, discover the ins and outs of serverless, learn how to design a NoSQL data model, make decisions on how to structure microservices, learn about cloud cost-analysis and predictions, and to top it all off - learn what multi-tenancy was and how to build an app that could handle it.
The list goes on and on of all the things we had to tackle and there certainly was understated nuance in there. But we loved it.
Of all the thoughts, concepts, architectures, frameworks, and design patterns we went through, probably one of the most fundamentally difficult things we went through was multi-tenancy. It wasn’t a concept new to us in theory, but putting it into practice was exhausting.
What Is Multi-Tenancy?
When talking about multi-tenancy, I always get the same question: “what is a tenant?”
Honestly, there is not a single correct answer to this question. For us, a tenant was a paying customer. For others it could be something entirely different.
This isn’t because our implementation of multi-tenancy was unique, it’s simply how we chose to add segmentation into our app.
A tenant is a group of users who share common access to a set of data.
In a multi-tenant environment, you have many (potentially unbounded) groups of users in your system that share the same instance of the software. These groups of users have access to the same set of data as each other, but do not have access to the data of other groups.
This paradigm is great for large applications because it cuts down on the complexity of release management. A shared instance implies you do not have a deployment for every customer.
Rather, you might have a single instance of your software deployed that everybody consumes. This increases the risk of disaster since there is only one release. So if one tenant sees a problem, everyone does.
A serverless implementation of a multi-tenant environment does not differ significantly from a traditional software deployment. However, there are some considerations to be made when we talk about scaling, how we go about authorizing users, and how we structure the data.
Serverless Implementation
To help illustrate the concepts, I have a GitHub repo of a fully functional multi-tenant app that we will walk through. This repo deploys a role-based serverless application that manages state parks.
Each one of the system-defined roles in the app allows access to various endpoints. An end user can be assigned multiple roles to extend their access to new features.
Users can belong to multiple tenants, but can only have one “active” tenant at a time. This reduces overall complexity around auth while also helping keep the data boundary of each tenant. By changing their tenant, the user is effectively changing the data they have access to.
With our reference application, a user can be assigned different roles based on the tenant. This allows for various access control where a user might have elevated privileges in one tenant but not in another.
Authorization
While Amazon Cognito has a range of multi-tenancy options, our example today will focus on a request-based Lambda authorizer to evaluate the caller’s identity and determine their active tenant. A Lambda authorizer sits in front of an API gateway, evaluates the provided auth token, and returns an IAM policy for the user.
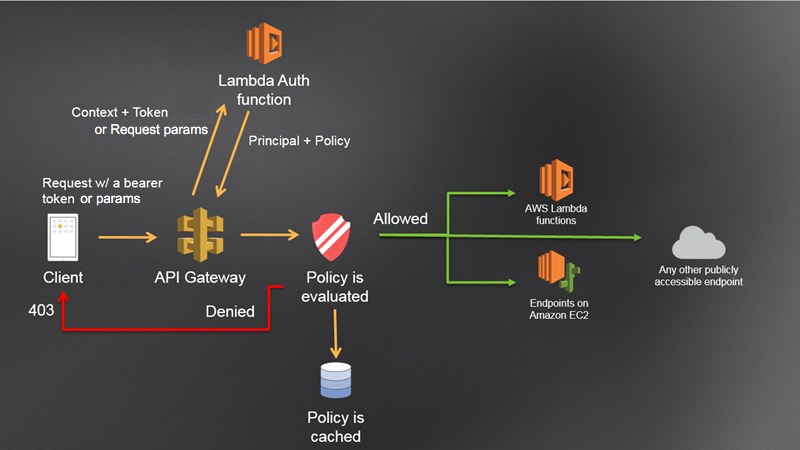
Lambda authorizer flow. Source: AWS
In our example, we will be making use of the authorizer context, which is enriched data passed into the downstream services as part of the authorizer policy. This data can be anything you want, and in our example includes details about the user making the call.
Here is an example of the request context data our authorizer returns:
{
"userId": "testuserid",
"tenantId": "texas",
"email": "testuser@mailinator.com",
"roles": "[\"admin\"]",
"firstName": "Test",
"lastName": "User"
}
The business process flow our Lambda authorizer follows is outlined in the diagram below:

- Validate JWT - The authentication mechanism in the workflow that validates the JWT provided in the Authorization header.
- Load user details from DynamoDB - After parsing the user id from the JWT, load the full user data from the database. This contains the active tenant, roles, and demographic information for the user.
- Determine access policy - Based on the roles of the active tenant, build an IAM policy of allowed endpoints the user can invoke.
- Build authorizer context - Build a data object containing information about the user to provide to downstream services like Lambda, DynamoDB, and Step Functions.
- Return policy and context - Pass the access policy back to API Gateway to evaluate and determine if the caller has access to the endpoint they are invoking
Once the authorizer completes and API Gateway evaluates the IAM policy, the backing services behind the endpoint are invoked and provided information about the caller.
Using the authorizer context provides an added layer of security in multi-tenant environments. It prevents malicious users from providing invalid tenant information and gaining access to data they do not own.
Since the tenant id comes from the authorizer, we’ve secured our API from certain types of malicious attacks where users try to spoof their tenant by passing it in their access token. The authorizer we’ve built loads the tenant information from the database, so any attempts at elevation are discarded.
The authorizer context is accessed differently based on the downstream service. With Lambda functions, we can access the enriched information via the requestContext object in the event.
exports.handler = async (event) => {
const tenantId = event.requestContext.authorizer.tenantId;
}
However, in VTL when we connect API Gateway directly to services like DynamoDB and Step Functions, it is accessed at a slightly different path.
#set($tenantId = $context.authorizer.tenantId)
Now that we have access to the tenant id for the caller, let’s discuss how we use it.
Data Access Control
The most important aspect in multi-tenancy is preventing users in one tenant from seeing data that belongs to a different tenant. Another way to say this is to have strong data isolation.
When data is properly isolated for a tenant, attackers are unable to manipulate API calls to return data across tenants. When it comes to structuring the data, it means we prefix all indexes with the tenant id.
Take the following data set as an example:
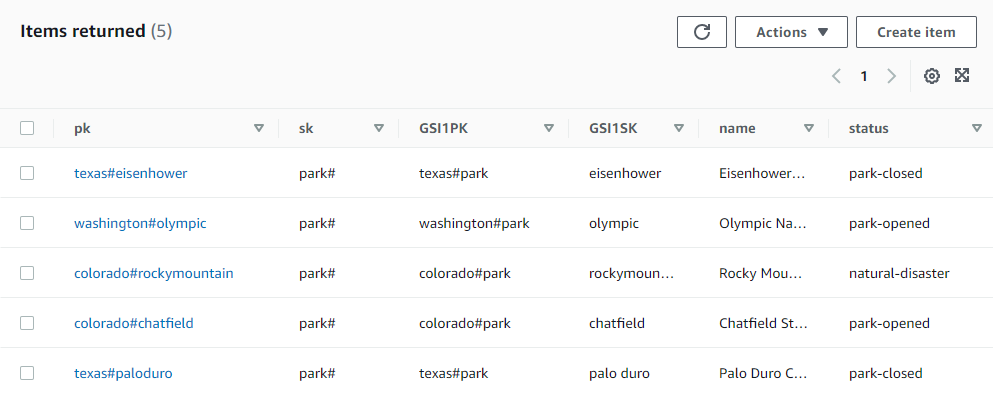
Data set of state parks across multiple tenants
In this dataset you have parks from three different tenants: texas, washington, and colorado. Both the partition key of the primary key and the pk of the GSI have the tenant id prefixed on the data.
Always prefix partition keys of the primary key and indexes with the tenant id in a multi-tenant application.
This pattern forces us to provide the tenant id when doing a GetItem or Query operation. By requiring the call to include the tenant id, you guarantee you will only receive data from a single tenant. You also guarantee you will get data for the correct tenant because the id you are using is coming from the Lambda authorizer and not spoofed from the caller.
NOTE - this pattern falls apart in table scans. You cannot guarantee access to a single tenant’s data when doing a scan. This is yet another reason why you should do scans as infrequently as possible!
Infrastructure Scaling and Service Limits
As you take on more tenants, your infrastructure will naturally scale in a serverless environment. But there are some components that you need to consider when doing your initial design.
In a previous post about avoiding serverless service limits, I talk about how there is an odd discrepancy with the amount of SNS topics vs the amount of SNS subscription filters you can have in your AWS account. You can create 100,000 SNS topics but only 200 subscription filters. Both of these are soft limits, but it is important to consider with a multi-tenant application.
Instead of having a set of static SNS topics that allows users to subscribe with a tenant filter, a safer solution would be to dynamically create SNS topics per tenant per event type. You get a slightly more complex solution, but you get the freedom of scaling without worry.
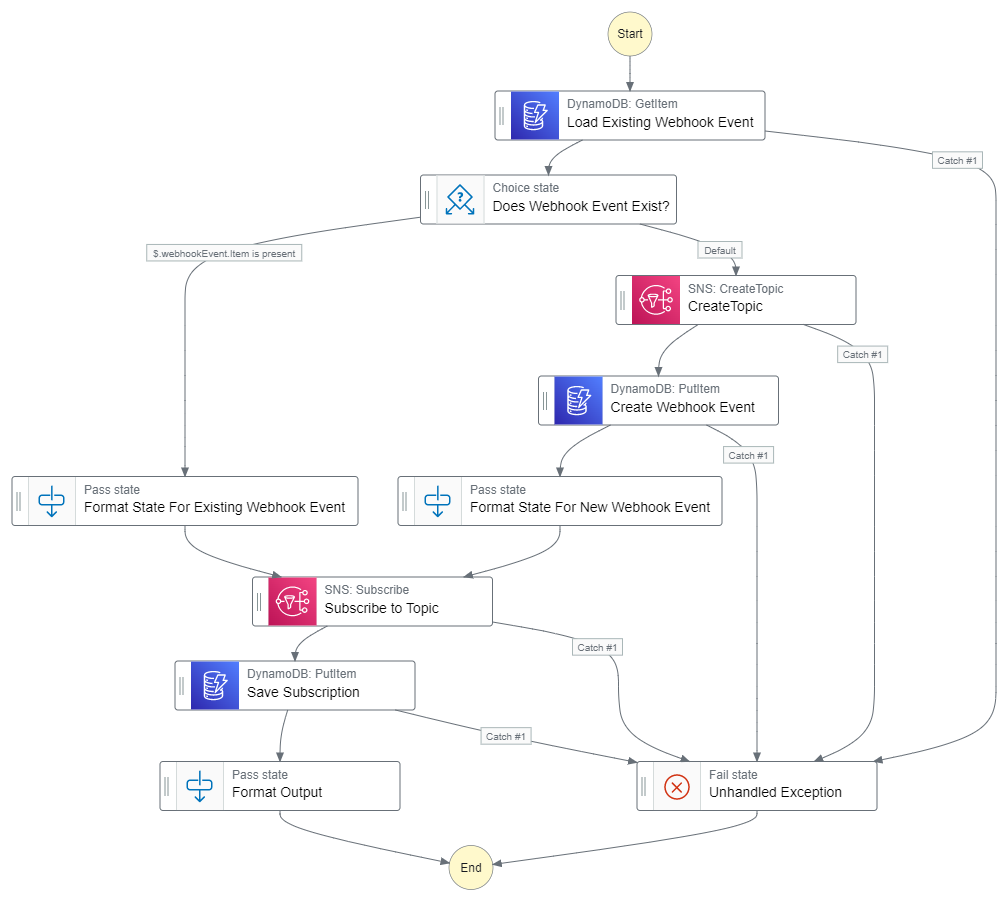
Workflow diagram of registering for a tenant-specific webhook event
These topics are created on demand as subscriptions come in, so you may never need to create topics for some event/tenant combinations. This pattern is illustrated in the subscribe-webhook workflow in the example repository.
When it comes to publishing the event to a dynamic topic, a simple lookup is performed to find the topic if it exists. If it does, we publish to it, and if it does not exist, publishing is skipped.
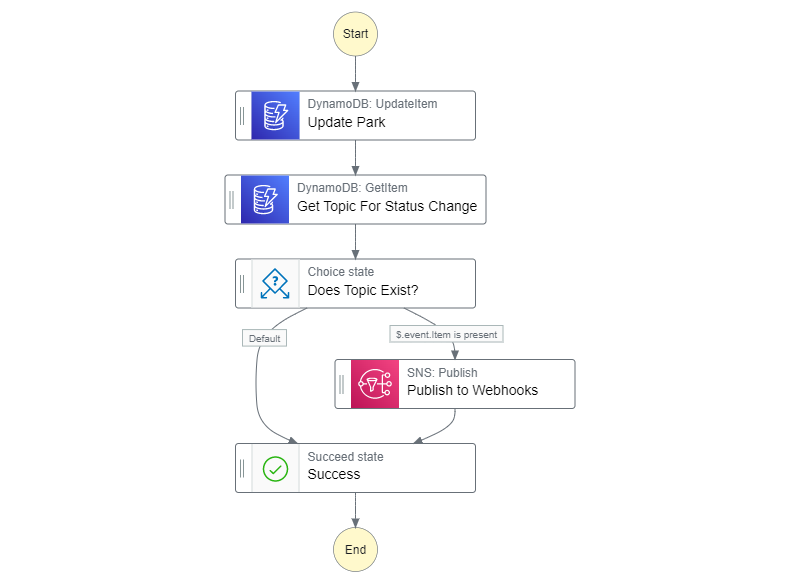
Workflow diagram of publishing to a dynamically created webhook event
When we talk about scaling out infrastructure for higher amounts traffic, your architecture changes considerably. At large scale, your application is more about batching, caching, and queueing than it is about anything else.
When you’re batching and queueing, you lose the synchronous nature of standard REST API request/response paradigms. This is an important consideration because your tenant id is being injected into the system from your Lambda authorizer. Don’t lose it!
When saving off messages in a queue to process in batch at a later time, you must keep track of which requests came in from which tenants. If you enable your end users to switch tenants at their discretion, looking up the active tenant at processing time is not an option.
It’s possible the user could have changed tenants between the time of the request and the time of processing. So your option is to save the tenant id along with the request when you receive it.
Working at a large scale isn’t too different from small scale strictly from a multi-tenancy perspective. As long as you are injecting the tenant id at a request’s point of entry, there is not much else that varies.
Conclusion
Going multi-tenant in your application certainly has trade-offs. You get decreased complexity and maintainability from supporting only a single instance of your application. But you get increased complexity by adding tenancy logic into your application.
Data security is also a concern with multi-tenancy. You must guarantee there are no accidental “slip ups” that return data to the wrong tenant. However, by prefixing the tenant id on all our lookups and avoiding table scans at all costs, we can mitigate much of the risk.
Watch for service limits as well. It’s easy to reach some of the lesser known limits as your application scales out with more tenants. It’s always a good practice to look at all the service limits of the services you will be consuming before you start building.
A tenant is a logical construct. How you implement it is completely up to you. As long as you keep your data isolated and build your app in a way that can scale, there’s no wrong way to do it. You can use Amazon Cognito and its incredible feature set, or you can take it on yourself for some fine-grained access control like I did.
Designing a multi-tenant application takes a significant amount of up front planning, but the ends justify the means. Hopefully the provided reference architecture will help spark some ideas for your implementation.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.