Test-Driven Development with AI: The Right Way to Code Using Generative AI
By Allen Helton04 October 2023
Unit tests are the worst. Don’t get me wrong, they are an invaluable part of any CI pipeline or automation. But man are they a pain to write.
Most developers I know, myself included, like to dive straight into code and would love to hand it over as soon as it’s functionally complete. But as those of us who have ever written something we have to support in production know, you can’t do that.
Alas, unit tests, integration tests, and end-to-end tests all need to be written to ensure that your code completely satisfies the business problem, covers all the edge cases, and is set up to maintain backward compatibility. It’s so important, in fact, that there’s an entire coding paradigm called test-driven development (TDD).
The premise behind TDD is that you write all your unit tests before you write any code. If you build your unit tests out completely making sure you cover all your business requirements, then you can test as you go. As you write the code your unit tests will stop failing, assuring you that you did what you were supposed to do.
When I was a development manager a few years ago, I thought this was a great idea. Senior managers and directors above me loved hearing about the hundreds of unit tests my team wrote and how we prioritized testing in order to maintain a high degree of quality. I pitched TDD to other teams and demonstrated how my team had success with it.
But I’ll let you in on a secret. We wrote the code first. Yeah, we weren’t building our tests then gradually watching them succeed as we implemented our functions. We coded and then wrote the tests. To make matters worse, we would squash commits when merging to main so nobody could tell 😬.
In hindsight, alongside being hilarious it was actually quite shady. I regret letting the practice slip away from us. We still had lots of unit tests, but it definitely wasn’t TDD.
Fast forward a few years to today where I’ve gotten even worse. I don’t manage dev teams anymore but I do write a lot of code. But these days I’ll write my code then ask ChatGPT to generate the tests for me. I was happy because at least the code had tests at all. Any tests are better than no tests.
Generative AI is great because it does exactly what you tell it to do. On the flip side, generative AI is bad because it does exactly what you tell it to do.
If you write a handler for an API endpoint that has a bug in it then ask ChatGPT to write unit tests for it, guess what you’re going to end up with? Yup, you’ll have a unit test that asserts the behavior with the bug.
You ship the code, unit tests pass, and it makes its way to production. Three days later you sit down at your machine welcomed by a Jira ticket describing the bug. Now you have to go back, fix the issue, update unit tests (yikes), and hope you didn’t miss anything else.
Giving ChatGPT your code doesn’t offer it business context. Generative AI thrives on context. The more information, aka context, you provide it, the better your result. But if you provide it with your user story and buggy code then ask it to write unit tests, you’re going to get mixed results. Sometimes you might get a response telling you the code doesn’t satisfy the requirements. Other times you might get back exactly what you asked for - unit tests of buggy code.
But what if we turned this process on its head? What if we used generative AI as the the piece that writes the code in TDD?
Developers Should Write The Tests
As much as I don’t like writing unit tests, there’s something to be said about their power. A unit test is intended to guarantee the behavior of a specific part of your code. This behavior is defined in your user stories.
Let’s look at a simple example of a user story for a train ticket reservation system.
As a customer, I want a simple way to reserve train tickets that let’s me pick a date and the number of seats I want.
Acceptance Criteria
I can only book tickets in the future
I can book tickets for rides today
I must reserve between 1 and 8 tickets (no alpha characters)
If there are not enough tickets available, I receive an error message indicating to select a different date
From this user story, you can deduce quite a bit of validations you’d need to build. These validations should all have unit tests associated with them. To name a few examples, with our story above we would have unit tests for the following:
Successful reservation
Failure when user reserves tickets for a date in the past
Failure when user reserves 0 tickets
Failure when user reserves 9 tickets
Success when user reserves 8 tickets
You can see where I’m going with this. You can build dozens of unit tests that validate behavior of boundaries, edge cases, and happy path.
When you practice test-driven development, all these unit tests are written first, carefully detailing every business requirement of the story.
Unit tests tend to be assumptive as well. As you write the tests, you assume some of the implementation details. For example, if your data lived in DynamoDB, your unit tests would need to mock out calls to the AWS SDK.
Not only that, but your tests assert the shape of the data as well. You should be validating all the inputs and outputs of your functions in both failure and success scenarios.
With this in mind, let’s talk about where generative AI comes into play.
Writing the Code
Now that we understand unit tests strongly define business requirements, assert request and response schemas, and include assumptions on underlying implementation, the next step seems pretty obvious - let’s give that to ChatGPT!
Your unit tests should be all the context the generative AI needs to take a stab at writing some code. Here’s an example prompt you could give it for a project written in Node.js:
Write a Node.js function handler that satisfies all the following unit tests in the most performant way possible but still easy to maintain long term. < unit tests go here >
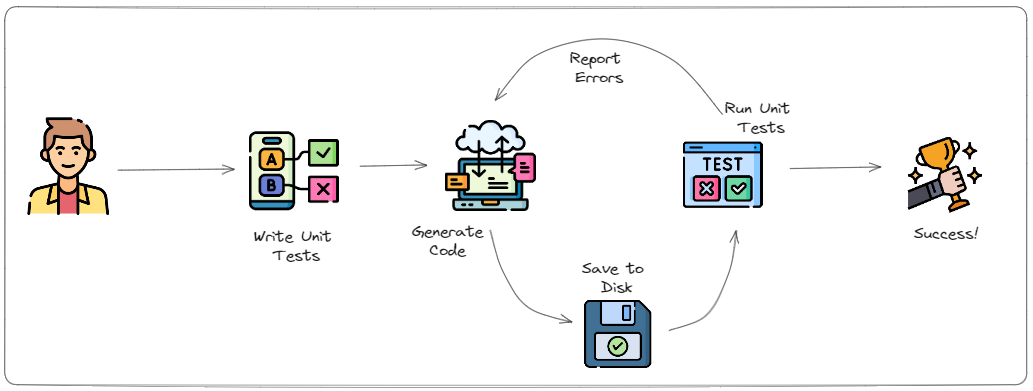
The response will be the source code that hopefully satisfies all the unit tests. Take it as-is and save it to disk.
But you’re not done! Now that you have the code, it’s time to put those unit tests to good use. Immediately run them and evaluate the code. If all your unit tests pass, you’re done! In the likely event you had a failure, it’s time to work some magic.
Your unit tests should have generated a set of results with the successes and failures of the run. Filter those results to only the failures and feed that back the AI, being sure to keep the full conversation history intact. By providing the full conversation history, you’re giving the AI context of what the unit tests are, the code it has written before, and what has and hasn’t worked.
This context is incredibly valuable as you iterate the code. The GenAI uses it to iterate and learn lessons from previous attempts. It gets to see what it tried, the results of the unit tests, and how updates it made to the code resulted in different (or the same) outcomes when running the unit tests again.
So the cycle becomes generate code, save code to disk, and run unit tests. If the unit tests fail, provide the outcome back to the generate code step so it can be factored into the next iteration.
This all sounds incredibly cool but there is a catch. It’s not perfect. You’ll need to change stuff here and there.
Unless you provide the AI with style guides or a reference, it’s not going to be written in your style - it might not pass linting rules. You’ll also need to take a pass and paramaterize certain values like database table names, connection strings, invoked resources, etc…
And thinking pragmatically, the AI isn’t going to always be able to write code that satisfies your unit tests. So you need to implement a circuit-breaker that will stop it from trying after a certain number of times. This will cut down on your feedback loop and also save you a lot of money.
Speaking of money, we need to talk about price. This one is a bit of a trade-off. In my early tests, GPT-4 did significantly better at writing code and rationalizing the requirements from the unit tests. GPT-3 never completely satisified all unit tests but GPT-4 did in 1 or 2 tries.
When it comes to pricing, GPT-4 is twice the price at $.03/1K tokens in and $.06/1K tokens out. Cost will vary wildly based on the amount of unit tests you have and length of code needed to complete them.
In the example I provided in my repo, I have 5 unit tests that describe the function I want written. Those tests plus the command consumed 941 tokens. The resulting output was 353 tokens.
If I needed to revise the code, I pass the entire conversation history in plus an extra comment describing what I want OpenAI to do. That means the prompt tokens on the second iteration are 941 + 350 + 50 (50 for the extra comment) with the resulting output being roughly 350 tokens again.
So the prompt tokens compound every iteration because of the conversational context you’re providing. So if you’re iterating 5 times, you’d consume approximately 10.5K tokens. At $.03 per 1K tokens, that means a single run of 5 iterations costs about $0.31.
If you use this dozens of times every day that could add up. Imagine you ran it 50 times a day, 20 days out of the month. Each run averages 5 iterations. The math would come out to:
50 runs x 20 days x $0.31 per run = $310/month
Now, depending on your hourly rate, that seems well worth the investment. If you’re saving even 30 minutes of coding time per run, that means you’d be gaining back 500 development hours in a single month! That math averages out to paying $.62 per hour of “free” development time. Seems like a pretty good deal to me!
All pros and cons aside, this is not intended to be perfect. If we can get AI to write our code with 80% completion and have it satisfy all our unit tests, then we’ve greatly sped up the productivity of developers. We aren’t looking to replace developers. We are looking to to make them faster. Take the undifferentiated heavy lifting from them so they can focus on business problems.
Write the unit tests. Focus on completely satisfying the business cases. Let AI do the grunt work. Developers take the generated code the rest of the way. Profit.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: