
Serverless
 Share on:
Share on:
Success With Step Functions - Finding a Way To Build That Doesn’t Suck
I am an advocate for using Step Functions when building workflows in AWS. I genuinely feel like it’s a powerful service that can handle many use cases better than Lambda.
For months I’ve been under the impression that I shared a common opinion from developers in the serverless community. That is, until I stumbled across this on Twitter:
ok when are we all going to confess that we just talk about step functions but never actually use them
— dax (@thdxr) September 8, 2022
Needless to say, I was a little taken aback.
Comments on that tweet indicated that he was not alone in that thinking. People seem to be talking about it less and less, trying to find other solutions, or just stop using it entirely.
This is a trend I simply don’t understand. I often hear talks about poor developer experience, the cost being too high, and more about poor developer experience. But I thought people were working around it.
Nope.
I won’t deny there are some “less than ideal” features that make it difficult to use as a developer. However, the functionality that backs it like automatic backoff/retry and AWS SDK service integrations seem well worth it while we wait for a more integrated DevEx.
Today I’ll cover how I’ve been using Step Functions so we can see why I still am trying to use them more and Lambda functions less.
New State Machines
When I have a project that requires a new state machine, I start in the Workflow Studio. The Workflow Studio is a visual builder hosted in the AWS console for Step Functions. Many developers will already complain at this step.
Despite the delightful experience of the Workflow Studio, the fact that it is not integrated into the IDE like Visual Studio Code, is a detractor from the DevEx for many. I’m not going to argue that it is not, but of all the workarounds I do in my day job for other things, I will gladly log into the console and use this tool when building a state machine.
Build The Skeleton
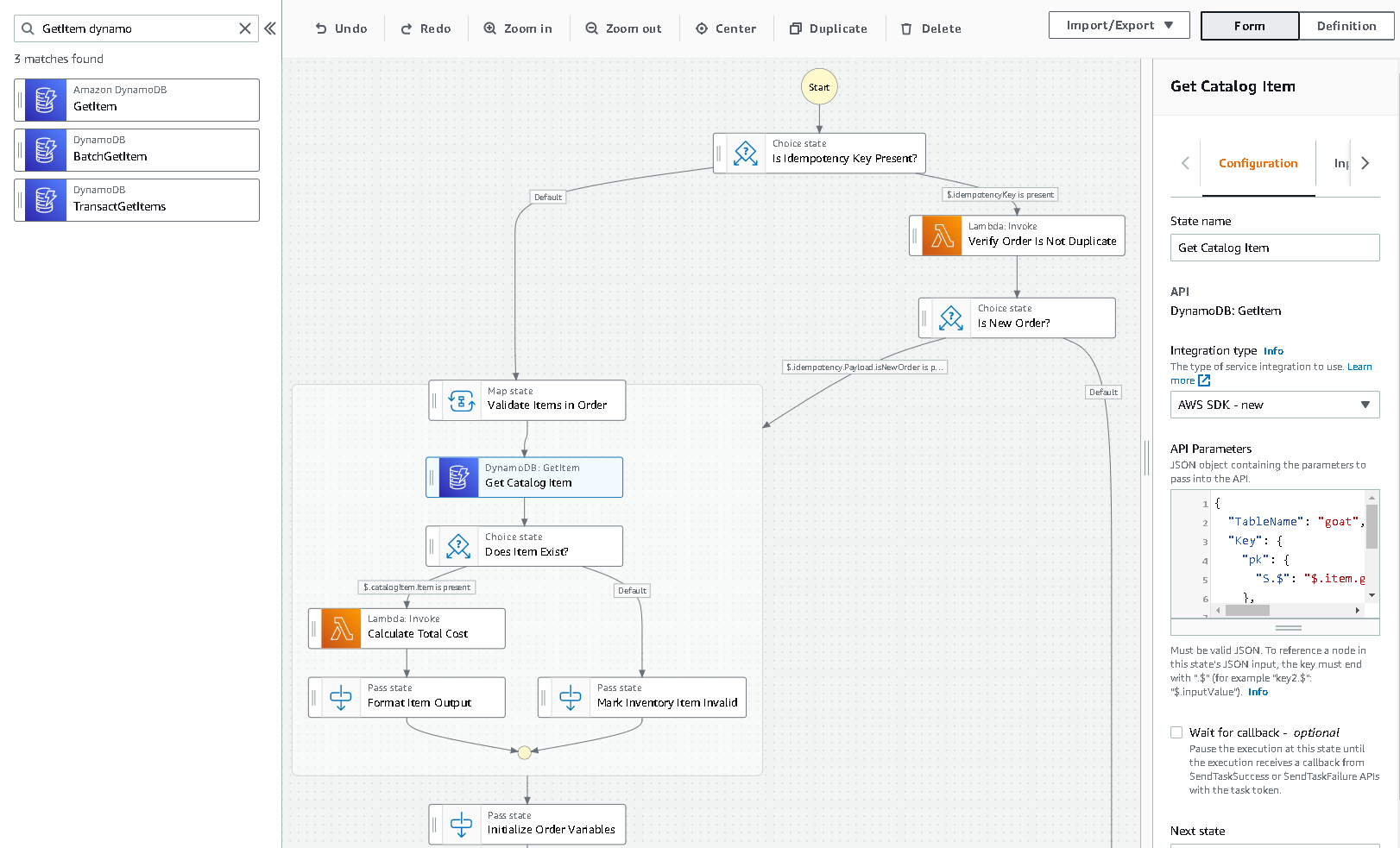
The builder allows me to drag and drop states on the screen so I can visually see the workflow of my data. I search in the filter for the SDK integration I want to use, like a DynamoDB GetItem call, and move it to the appropriate spot in the workflow.
Finding the right SDK call in Workflow Studio
As I build the workflow, I am sure to appropriately name each state for easy maintainability in the future. If I left the default name in the states, it would be impossible for other developers to figure out what the workflow was doing.
In our skeleton building phase, we aren’t focused on anything more than the data flow. What pieces are going to process the data in what order. In other words, “this happens, then that happens, then these things happen at the same time.” The point of this phase is to see your workflow represented graphically.
Seeing it in front of you helps strengthen your conceptual design and starts exposing any issues you might have had in your original thinking.
Once you’ve laid it out and worked through the initial gaps, it’s time to actually make it work.
Wire It Up
Now that you know how the data is going to move, it’s time to think about the data itself. What data is required when you move from state to state?
SDK Data
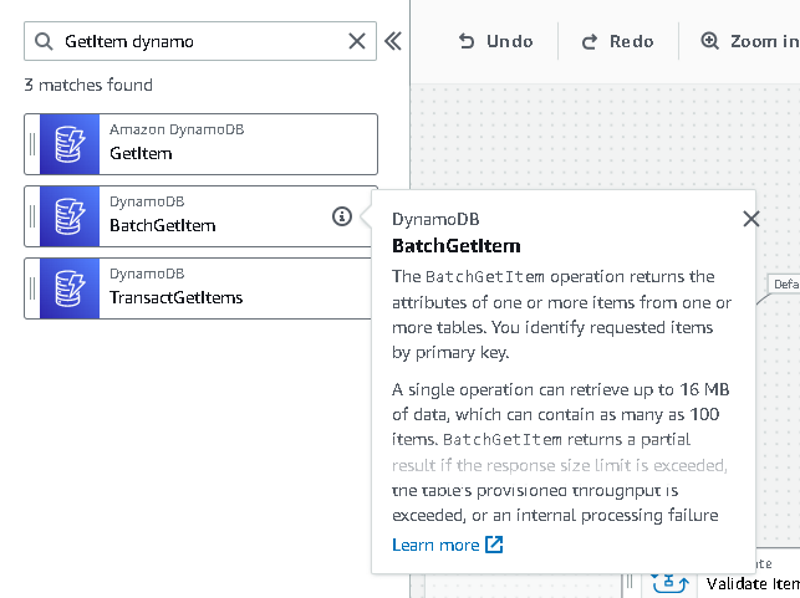
How do you know what data to include when calling an SDK integration? This can be a little confusing at times and definitely detracts from the user experience. Once you drag the integration you want into the designer, it’s up to you to read the API documentation to figure out the fields that are available for use.
The Workflow Studio does its best to include the required fields by default for an SDK integration. But there is often significantly more to the call than just the required fields.
I’ve had issues with this in the past. I would read the documentation for API call, try to use a field, then when I go to save I would get an error. This is because Step Functions uses the Java SDK for integrations. Capitalization and available fields must match how they are defined in that SDK. When I was having issues it was because I was using the Javascript SDK as a reference point, which has minor variations in the capitalization.
SDK Integration hint in the Workflow Studio
The Workflow Studio gives you a description of the SDK integration you have selected and a link to the API documentation as a launch point. It’s up to you to take what you read and incorporate it in your state machine. Again, it’s a disjointed experience, but it does try to help you as best it can.
State Data
As a general rule, only keep the minimum amount of data across state transitions.
In my post on the pitfalls of Step Functions, I spoke about the max data size a state machine can transfer from state to state. This means you must make a conscious effort to keep the amount of state data small as your workflow runs.
Each SDK integration will return a response. You must decide if you want to throw the response away, keep all of it, or keep some of it. You can do this by getting familiar with ResultSelector, ResultPath, and OutputPath.
These processing components allow you to selectively choose pieces from a task result and add them into your data object to pass to the next state. Don’t worry if you lose part of the original state machine input. If you need it in a downstream state, you can access it via a context variable at any point.
Imagine you had the following input to your state machine:
{
"customerName": "Allen Helton",
"email": "allenheltondev@gmail.com",
"order": [
{
"id": "k9231af824j",
"quantity": 1
}
]
}
At the end of the workflow, if I wish to send the user an email with confirmation of the order, it doesn’t matter what’s currently in the state data. I can always access the email address with the path $$.Execution.Input.email.
Managing state data is one of the most important design considerations when building Step Function workflows.
By managing state data, you not only avoid an unnecessary failed execution due to an overflow, but you also improve the readability and maintainability of the workflow long term. Removing the unnecessary data from the workflow will make it easier for developers to troubleshoot in the event something goes wrong.
Test It
As with all code we write, we need to test the state machine before we deploy it to production. The beauty about designing directly in the console is that you can immediately run your real workflow to iron out the kinks.
You can hit the Start Execution button, pass in your expected input, and watch the flow. If you’re using a standard workflow, you can see how the state data takes shape between states and you can easily view the path the workflow took.
If you’re using express workflows, you once again have to use a different tool if you want to see the visualized data. Express workflows only record logs in CloudWatch as compared to standard workflows that show you beautiful renderings of the execution.
In the event that you’re like me and have a slew of issues the first several times you run it, that’s ok!
First, welcome to the club. Second, if your issues are a result of managing state data (as mine often are) you have the data flow simulator that will show you exactly what the data looks like at each phase of the transformation in any given state. This allows extremely easy debugging and data paring to get that minimal state size we spoke about earlier.
Once you’re happy with the tests, it’s time to prepare the workflow for source control.
Parameterize The Workflow
Every time I talk to someone about Step Functions I hear some form of “I hate manipulating the state machine json.” Honestly, this comes from a reasonable concern, managing a state machine directly out of the json can be a daunting task, especially for larger workflows.
The Workflow Studio allows you to export the definition as json or yaml, but the export does not have any parameterized values. It hardcodes the references to resources directly, which is not the ideal situation when you use Infrastructure as Code (IaC).
Since we always promote IaC as a best practice, it’s not an option to always build directly in the AWS console. We need to take the workflow definition, parameterize it to deploy into any AWS account, region, or partition, and put it in source control.
This part could take a considerable amount of time if doing it by hand. So I wrote a script to do it.
In this gist, I have a script that takes a raw state machine definition file and parameterizes all of the appropriate Resource tags. It also takes a best effort guess at parameterizing values contained in the SDK integrations themselves for resources that might be included in your stack.
It takes the substituted values and creates a SAM definition of the state machine with a best guess at IAM permissions.
The script outputs both the SAM definition and the updated diagram json for you to put directly into your stack with as little modifications as possible.
From here, we’re done! That is the end to end process to create a new workflow definition with Step Functions.
Existing State Machines
I’ve mentioned a couple times already to take maintainability into consideration when designing your workflows. The initial development of your state machine is only the beginning of its life. There will be bugs (whether we admit it or not) and enhancements made on top of your work.
Maintenance and enhancements will be most of your state machine’s life. Or any of your code, for that matter.
Luckily for us, we’ve already covered most of what goes into maintenance.
Start With Workflow Studio
When making an enhancement to an existing state machine, start in the AWS console. The goal of these processes is to keep you out of the state machine json as much as possible.
From within the AWS console, select the existing state machine. Open up the Workflow Studio to get going with your enhancement.
As you make your change, remember to pay it forward. We originally built the state machine with intuitive state names. As we build on top of it, continue to include meaningful state names. Nobody wants to get into a workflow and try to figure out what Pass (8) does.
It should go without saying, but I’ll make sure to say it anyway. Do not edit state machines directly in production!
Since the state machine has already been wired up appropriately, I tend to skip the skeleton step. When modifying existing workflows, I pass in the appropriate data to the SDK calls and trim the output as I add new states. Since I already know the shape of the incoming data to the states, it’s easy to grab what is already there and use it.
Test Your Updates
Just like you did when you were building a new state machine, you need to test the changes. The benefits of making modifications to an existing state machine is that you can use inputs from real executions to run your tests.
If you go to the execution history page in the console, you can click on any of the executions and grab the input. Use the input to run a test with your modifications.
WARNING - If your state machine input contains PII or other sensitive information, please be cautious when using input from prior runs.
Export and Replace the Definition
Use the export functionality from the AWS console to get your new definition file. Run the script just like we did before to parameterize the definition file and create the SAM definition.
You can then replace both pieces in your repository with the newly generated components. If there were any manual changes on the original, you would need to make those changes again or update the script to reflect the changes you made.
Now when you create a pull request, hopefully the diff will only show the json for the updated and new states. This makes it a much more manageable task.
Other Considerations
There’s a thought going around that Step Functions are too expensive to use in production. Well, it depends on how you’re using it. I did some research on cost and performance of Lambda vs Step Functions and the results are surprising.
When it comes to express workflows, the cost is negligible. Often times the cost is lower because Step Functions execute faster than Lambda when using direct SDK integrations.
With standard workflows, price is per state transition. If you have large workflows that run millions of times a month, yes it will be expensive. But consider the tradeoff. Instead of managing giant Lambda functions or container images to orchestrate tasks, you can navigate to the Step Functions console to walk through exactly what happened in a complex action.
Total cost of ownership (TCO) comes into play when talking about enterprise production software and maintaining it over the life of your application. Being able to jump straight to issues instead of spending hours trying to debug is invaluable.
On another note, Step Functions are not a silver bullet. They don’t solve all your problems. Sometimes a Lambda function fits better in a given scenario. For example, if you have only one or two actions you need to perform in a given task, that might be a better use case for a Lambda function.
When I am building something, my general rule of thumb is if there are three or more SDK calls, move it to Step Functions. It results in a better, more reliable product long term.
Summary
I agree that the Step Functions service has a disjointed developer experience. However, we have workarounds and processes that make it a reasonable service to use in production.
Like all cloud services, Step Functions will continue to get better. They will continue to release better features and better integrated tools. This service takes an enormous amount of complexity and boils it down to an impressive level of abstraction. As the service team gets better acquainted with the problems that come up and the community delivers consistent feedback, things will continue to get better.
Don’t confuse complexity with unfamiliarity.
I see a lot of comments out there on the nightmare that is hooking up Step Functions with VTL. I agree, that’s not an easy task. But it’s a solved problem. It’s something you can find references on to become more comfortable with.
All this to say…. it takes practice. Give it a chance and you can find long term success. Don’t just talk about it, use it. That’s what I’ve done and it has quickly become my favorite AWS service.
Happy coding!


{kind=link}
{kind=link}
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.