
Solutions architect
 Share on:
Share on:
The Solution Architect’s Guide to Serverless
For years I’ve been proud to say I build 100% serverless cloud applications. I wore it as a badge of honor that the software I designed could elastically scale at every tier and cost virtually nothing to run at small to medium scale.
I used to introduce myself to people in tech as a serverless architect and make a best effort to build apps with Lambda, Step Functions, or direct integrations through API Gateway as the only form of compute.
But I was wrong in my thinking. That’s not necessarily the ideal way to build software. The best way to build software is the one that solves the business problem with the lowest total cost of ownership.
Yes, serverless services are great, but let’s be honest - not every business has the budget to upskill its entire engineering staff. Nor do they have the appetite to refactor everything to be completely serverless, and that’s ok. I’m going to assume you’re here because you’re interested in incorporating some serverless components into your existing stateful applications.
Setting the Record Straight
First, we need to address some information floating around the internet about serverless services. I’ve had many conversations with people that are dismissive around the topic because they are misinformed, operate under false pretenses, or fundamentally don’t get the point of serverless. You may or may not have heard a few of these.
They are only for serverless apps
Probably the biggest myth out there is that serverless services are designed exclusively for serverless applications. This is not true! You can use serverless services in any software, be it a Kubernetes-based app, an on-prem solution, or a serverless API. These services provide serverless capabilities, like pay-for-what-you-use, elastic scaling (including down to 0 when not in use), and simple “it just works” control/data plane operations.
You can use services like Amazon DynamoDB or MongoDB Atlas as your primary data store in a container-based application. These serverless database services are intended to simplify development and long-term maintenance by providing simple APIs to do powerful operations. They abstract away hardware maintenance and management from you so your engineering teams can focus on something more important - solving the business problem.
They are prohibitively expensive “at scale”
I used to get this from senior leaders at big enterprises. First of all, not many people can articulate what “at scale” actually means. Does it mean the number of paying customers? Does it refer to the amount of traffic coming into your app? Is it the number of daily active users? Even if we all agreed on what “at scale” referred to, perspective plays a large part in the equation as well. For a startup, “at scale” might refer to 100 transactions per hour. For large, multi-tenanted enterprises, it might mean 10,000 transactions per second.
I did some math last year while researching this topic. I compared the cost of a small serverless app with its equivalent container version. It’s a bit of an apples-and-oranges comparison but in my example, the costs didn’t become more expensive to run on Lambda until you reached around 66 transactions per second. Note that this varies significantly on implementation and as your traffic increases, so do the requirements on the virtual machines running your software.
Cold starts are non-starters
There was a point in time where every talk I gave on serverless had at least one heckler say “what about cold starts?” It’s a term people latched onto and blew out of proportion. Cold starts are a byproduct of serverless compute. When an invocation results in a new execution environment being spun up, the time it takes for the environment to be functional is referred to as a “cold start”.
For some reason, many people assume they take several seconds and that the majority of calls to a serverless API result in cold starts. Unless you have consistently spikey workloads, this is not the case. Consistent traffic will rarely result in a cold start. As for duration, you can see for yourself they range from ~18ms to ~500ms depending on the runtime you use.
Many workloads will tolerate the intermittent latency hit of a cold start. The delay is often minimal and is typically only seen during periods of inconsistent traffic.
You’ve never used serverless before
I have a surprise. You’ve probably used a serverless service and didn’t realize it. Ever use Amazon EC2? Your AMIs are stored in S3, which is a serverless service. Have you sent a using Twilio’s API? They are serverless.
Serverless services are all around us and are a critical part of everything we use. Whether you’re using a serverless service directly or using a stateful service that uses one behind the scenes, if you’re building apps in the cloud - you’re already taking advantage of these services. You don’t need to be afraid of them!
Design Considerations
Now that we cleared up some of the concerns around serverless and understand we’ve probably been using these services for a while, let’s talk about a couple of design considerations when introducing serverless into our stateful apps.
Elasticity matters
When building an app with serverless services, an interesting gotcha is that sometimes the services scale too well. If you’re building a serverless API that posts to a webhook backed by EC2, you better make sure they scale at the same rate or have a way to throttle incoming calls!
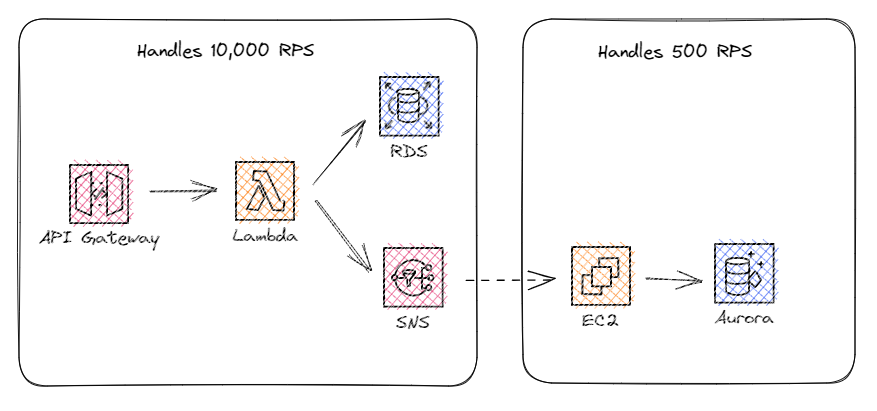
In the above example, we had an existing application living in EC2. Our enhancement added a serverless API that acts as a point of ingress. It does validations and enrichments before publishing a webhook to trigger an existing process in EC2.
The new serverless API and backing services will scale up to 10,000 requests per second (API Gateway throughput service limit). The Lambda function uses SNS to publish to a webhook exposed by the EC2 instance. The size of the EC2 instance can only handle up to 500 requests per second.
If you get a large spike in traffic, the serverless API will scale up to meet the demand. It can successfully process the 10K requests every second and push messages to EC2 orders of magnitude faster than it can handle. This overloads the instance and you’ll end up dropping events and ultimately having significant data loss.
To mitigate the risk of overflowing your app, you can add an SQS queue in front of your EC2 instance to act as a message buffer. Messages go into the queue directly from the serverless API and the EC2 instance pops items off at a rate it can handle.
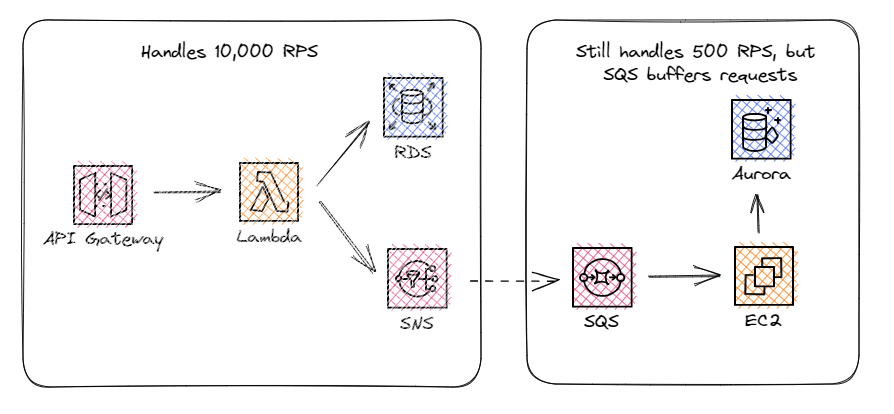
It’s important to note that if your serverless API is consistently pushing items into the SQS queue faster than EC2 is reading them, you’ll build up an ever-growing backlog of events. In this scenario, your EC2 instance should be scaled up to work items faster than they are coming in.
Start with orchestration
Serverless works best with event-driven architectures. It seamlessly builds decoupled services that operate independently and asynchronously. But if you’re introducing these concepts to a team that’s never done them before, it can be overwhelming.
A way to ease your engineers into event-driven, async software is to orchestrate workflows with a service like AWS Step Functions. This service lays out all the actions in a workflow right in front of you. You can track how data transforms from step to step and easily build in compensating actions when failures occur.
In the AWS console, every execution of a Step Function workflow will show you the path the data traversed so you can quickly see what happened in a particular instance. It makes for easy debugging and introduces the concept of modular, multi-step processes to your engineers. Here’s an execution diagram from my blog cross-posting workflow.
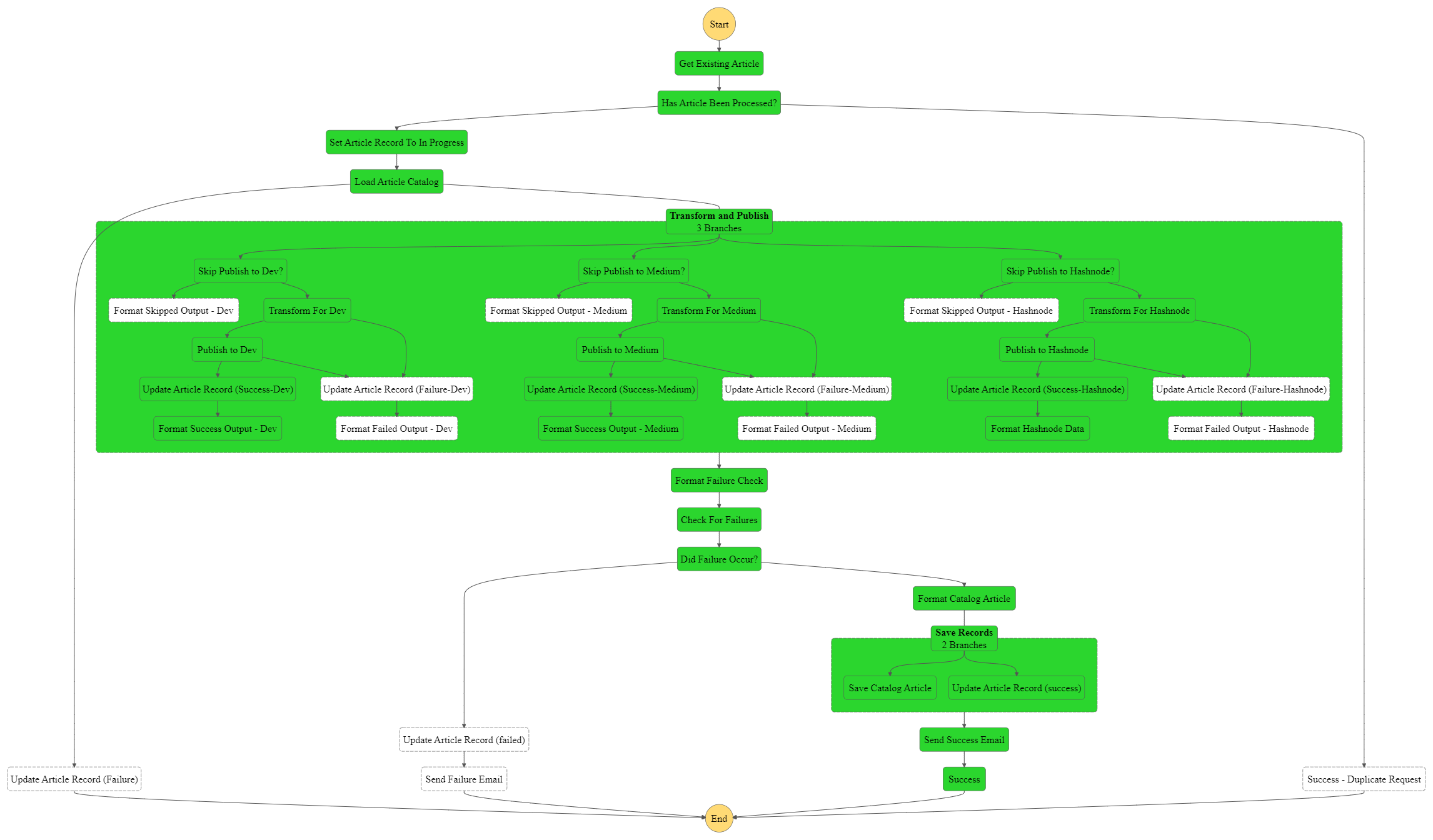
This diagram shows exactly what happened when my blog was posted to other sites. The green blocks indicate that step was executed while the white blocks were skipped. I can click on any of the individual blocks and view how the data was transformed from step to step.
Views like this educate engineers by showing them step-by-step workflows. It helps them realize not everything needs to be done in a single file. The spirit of serverless is modularity, where functions are small and perform a single, independent task. Using an orchestration engine like Step Functions is a great way to drive best practices while slowly introducing core event-driven architecture concepts.
Once you’re comfortable with building business process in pieces, you can start introducing choreography into your apps, which decouples services even more by following a pub/sub event pattern.
Design for retry
Failures happen. That’s part of software development. When using serverless services, the default behavior in many of them is to retry an operation when a failure occurs. This happens automatically and could result in duplicate data entering your stateful application.
Build idempotency mechanisms into your application. These mechanisms handle input de-duplication typically by using an idempotency key to identify payloads. If a payload comes in with an idempotency key your application has seen before, it will skip processing and return the result from the original invocation.
Automatic retries can result in some head-scratching moments if you’re trying to debug an issue and aren’t familiar with the concept. It’s also near-impossible to reproduce. But by building idempotent handlers, you can save yourself some heartache and improve the resiliency of your app at the same time.
As you get comfortable with failure (be it network-related, code-related, or something else), you can even build your own retry processes.
Summary
Serverless services work well in completely serverless applications AND in stateful applications. Serverless refers to a set of capabilities that services provide, it doesn’t define applications built on top of them.
If you’re a solutions architect and exploring the idea of integrating with a serverless service for the first time, my only advice is - do it! As with everything in software development, it comes with tradeoffs. That said, these services offer tremendous benefits like instant elasticity, unrivaled availability, and inexpensive pay-for-what-you-use pricing.
You can use serverless at any level of a stateful application. Just be careful not to overwhelm your services by opening a floodgate of events. Buffer calls that come in faster than you can process them. Introduce your engineers to one new concept at a time. Get to know the intricacies of it before introducing another new one. Learn as you go.
If you’re intrigued by the idea of serverless but still not sure where to start, feel free to reach out to me and ask questions. I’m always happy to help and love introducing people to the wonders of serverless.
Happy coding!


Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.