Serverless

Best Practices for Building Serverless Microservices
Microservice is a funny word.
Not in the sense that it sounds funny or is spelled funny. But in the sense that most devs know what it means, yet they have no idea what it actually means.
Even if you’ve never heard the phrase before, context clues are pretty easy. It’s a small service. But what does small mean?
Small in size? How big does the it have to be before it’s a mediumservice?
There’s so much more to a microservice than the size. You have deployment, repository structure, domain, maintainers, coding conventions, etc… There is a significant amount of decisions you need to make when deciding to go with a microservice architecture.
What is a Microservice?
Simply put, a microservice is an independently iterable piece of software.
They typically are pieces of a larger application. It should not have hard dependencies that require other microservices to deploy at the same time. It needs to be able to deploy in isolation.
That said, it is totally acceptable for a microservice to have dependencies. If you have a microservice that triggers a workflow on an event from another microservice, that is a loosely coupled dependency. There is a big difference between a deployment dependency and a functional dependency.
Functional dependencies require other services to exist in order to satisfy the business problem, but not in order to be deployed.
How do you decide which microservice produces events and which one consumes them?
Microservices should be domain driven, meaning they are responsible for one type of thing. In other words, this type of architecture creates a separation of concerns for your business logic.
In the classic “shopping cart” example, you have a handful of microservices, each with their own responsibility.
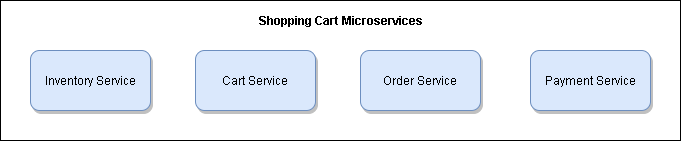
Four microservices that make up a shopping cart app
The microservices above are each independently iterable when it comes to enhancements and have loose coupling between them to handle saga workflows. But the point to note here is that each microservice is responsible for one thing. Micro stands for a small amount of responsibility, not a small amount of code.
Serverless Best Practices
When looking at serverless, microservice architectures fit incredibly well. Serverless lends itself well to single responsibility, focused work - which is what microservices are all about.
The following best practices are intended to be used as guides. These have worked well for the teams I have been a part of, but might need minor adjustments when you apply them to your projects.
Repositories
There are two schools of thoughts when it comes to structuring your repositories for an application: monorepo vs multiple repos.
A monorepo is a single repository that has logical separations for distinct services. In other words, all microservices would live in the same repo but would be separated by different folders.
Benefits of a monorepo include easier discoverability and governance. Drawbacks include the size of the repository as the application scales, large blast radius if the master branch is broken, and ambiguity of ownership.
On the flip side, having a repository per microservice has its ups and downs.
Benefits of multiple repos include distinct domain boundaries, clear code ownership, and succinct and minimal repo sizes. Drawbacks include the overhead of creating and maintaining multiple repositories and applying consistent governance rules across all of them.
In the case of serverless, I opt for a repository per microservice. It draws clear lines for what the microservice is responsible for and keeps the code lightweight and focused. One of the AWS serverless design principles is to share nothing, and separating your microservices to individual repositories makes it easy to not accidentally do something you shouldn’t.
Folder Structure
The folder structure in a repo is crucial to proper organization. Make sure your code is structured in a way that allows for easy discoverability and maintainability over time.
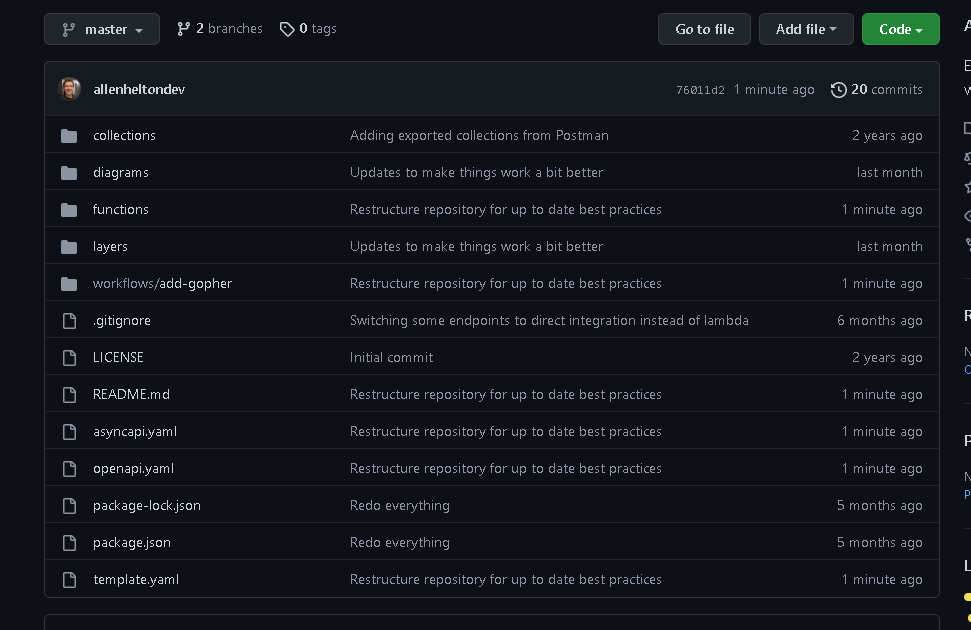
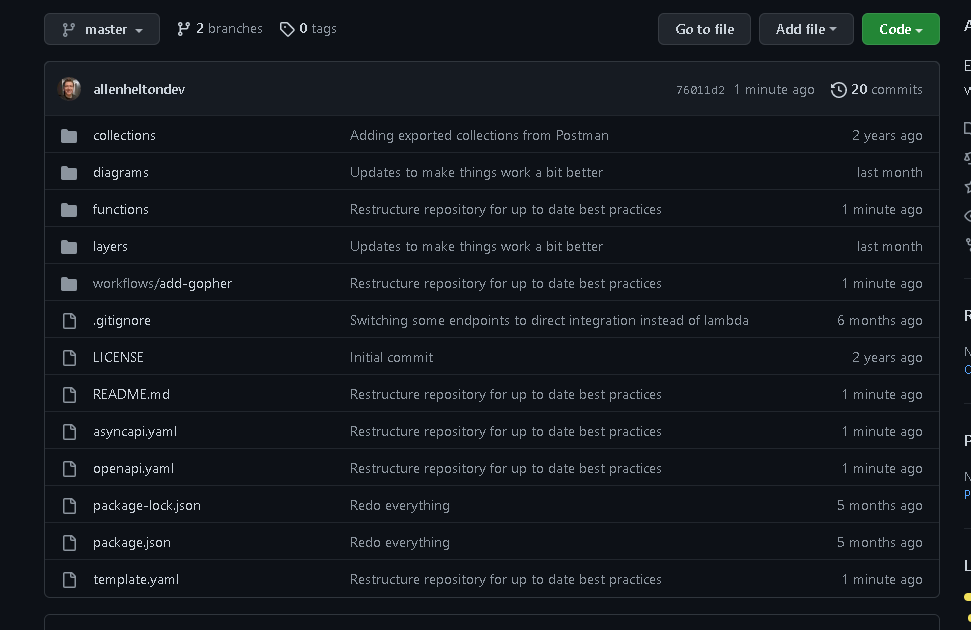
With serverless microservices, structure your root-level folders by resource type. Take the Gopher Holes Unlimited reference architecture project as an example.
Serverless microservice layout
All Lambda functions are contained in the functions folder. Similarly, Step Function workflows are contained in the workflows folder. Lambda layers are contained in the layers folder, and so on.
Organizing your code by resource type helps developers quickly jump to a specific bit of code.
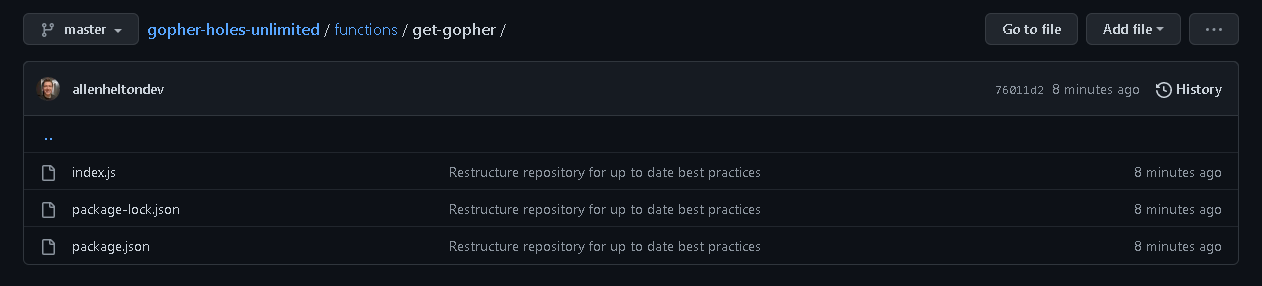
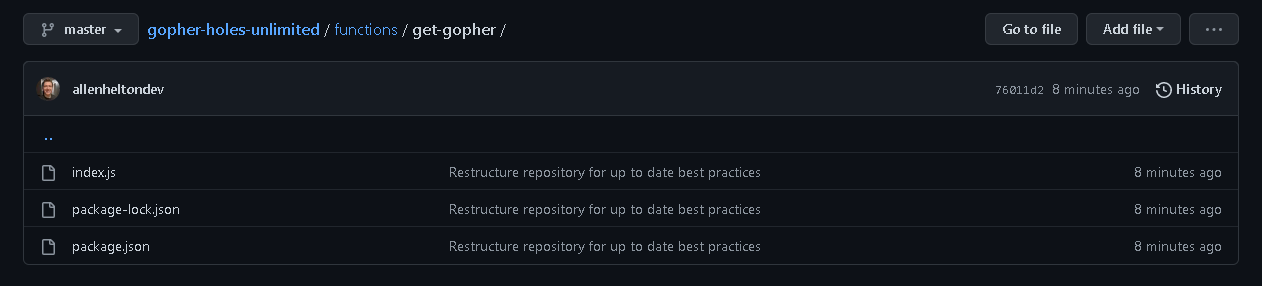
Within each one of these top level folders are subfolders containing everything necessary for the individual resource.
Subfolder containing all files necessary for a Lambda function
Take the above folder for the get-gopher Lambda function as an example. It contains an index.js, package.json, and package-lock.json. This means each function can have completely isolated dependencies, allowing you to reduce your Lambda package size which ultimately reduces cold start time.
Handle the dependencies of each one of your functions separately. If the majority of your functions use the same set of packages, put them in a dependency Lambda layer and use the layer across your functions.
Cloud Resources
In theory, a microservice should not have any hard dependencies. This means that it should be initially deployable without prerequisites.
With this in mind, a serverless microservice should be completely self-contained. This means that it contains resources for all Lambda functions, your DynamoDB table, KMS keys, APIs, etc. Remember, share nothing.
When I first started out, I thought it would be a good idea to share KMS keys across all the microservices I deployed in an AWS account. I created a shared-resources microservice and exported values from the stack that I would consume in other microservices.
This led to some poor behavior very quickly. I thought since I did it once and it was fine, I could do it again. Before I knew it I had deployment dependency hell, circular references, and an extremely specific order services needed to be deployed in.
Don’t do that.
Pay the extra $1/month to have a unique KMS key in your microservices. Security is always worth it.
When it comes to defining your resources, everything should be declared as Infrastructure as Code (IaC). This allows you to consistently deploy the same set of resources into any region in any account.
There is no best practice on the type of IaC you use, whether you use SAM, CDK, Terraform, Serverless Framework, or Pulumi, as long as you have it defined in some way that makes sense to you, that is the best way. In the future, we might not even need IaC!
Conclusion
Microservices and serverless go hand in hand. They narrowly scope responsibilities, provide a way to separate concerns, and offer an easy way to stay agile and quickly deploy to production.
With everything in software, there are tradeoffs with the decisions you make with your microservice implementation. Going with a repository per microservice offers fine grain control over deployments, clear domain definition and code ownership, and a concise codebase with low risk of accidental “spaghetti code”. But you lose some of the service discoverability if you went with a monorepo.
Staying organized is one of the keys to long term success with any project. After the initial development team has moved on from the project and the long-term maintainers roll in, will they know what you did and how to find code? Having a well-defined folder structure improves the maintainability of your app over time. Structure your microservices by resource type so maintenance developers know exactly where to look when issues arise.
Build self-containing services. Don’t build stacks that require resources from other services in order to deploy. However, you can (and should!) build microservices that depend on others to satisfy business processes through loose coupling via API calls or events.
If you’re looking to get started with microservices, don’t forget they are driven by domain. When looking to “break up the monolith” start by identifying the discrete pieces of your application. Find the areas of the application that have enough business logic to be on their own and iterated separately from everything else.
If you get a couple years in and realize that two microservices should have been one or a service has gotten so big it needs to be split, do it. The beauty about software is that it gets better every time you revisit it.
Use what I outline above as a guide. What works for my team might not work for you and your team. But using it as a reference point will get you off the ground and start building experience.
Happy coding!


{kind=link}
{kind=link}
Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.