Serverless Speed Test: Comparing Lambda, Step Functions, App Runner, and Direct Integrations
By Allen Helton10 May 2023
When it comes to serverless development, we all know you have options. There are 10 different ways to solve any given problem - which is a blessing and a curse. How do you know which one to choose? Are you comfortable with the trade-offs of one over another? How do you decide?
Every opportunity I have to remove Lambda from the equation, I take it. Not because I don’t like Lambda, quite the contrary. But if I get the chance to alleviate some of the pressure on the 1,000 concurrent execution service limit, I’ll jump on it.
A few months ago, I wrote a blog post talking about direct integrations from API Gateway to various AWS services. This skips Lambda functions entirely by going directly to DynamoDB, SQS, EventBridge, etc… This is an appealing alternative because there are no cold starts and supposedly it scales as fast as you can throw traffic at it.
If you follow my writing, you know I’m also a big Step Functions fan. Last year I did a benchmark comparing Lambda and Step Functions on cost and performance. It was an interesting article where I try to decide mostly from a cost perspective how they compare in various scenarios. I have a general rule of thumb that if I need to do 3 or more SDK calls in a single operation, then I should use a state machine rather than Lambda.
And then, of course, there is App Runner. This service feels like the next iteration of FarGate to me. It’s a serverless container service that handles all the load balancing, container management, and scaling for you. You just punch in a few configuration options, throw in some code, and you’re done.
But which one of these is the fastest? What can you back your endpoint with to get the quickest, most reliable performance? I haven’t seen direct comparisons of these services before, so how would you know which one to use for your app if you wanted a lightning fast API?
Let’s find out.
The Test
I want to compare direct integrations, synchronous express Step Function workflows, Lambda, and App Runner to see which one consistently returns the fastest results. To do this, I built an API with a single endpoint that points to each one.
App Runner creates its own API, so it’s treated separately.
I seeded the database with 10,000 randomly generated turkeys. Each turkey is about .3KB of data and has information like the name, breed, weight, etc.
The test runs a DynamoDB query to get the first page of results for a particular turkey breed. The call hits a GSI and returns a transformed array of results. We can reasonably expect about 115 turkeys every time we make an invocation. So it’s a basic endpoint, but just a step above a “straight-in, straight-out” approach.
To test the latencies and scalability, I wrote a script that calls the endpoints and measures the round trip time. It records the total time and the status code of the calls. After X amount of iterations, the script calculates p99, average, and fastest call. It also calculates what percentage of the calls were successful, which will help us figure out scalability.
Configurations
It’s important to note that the results we’ll see below vary based on configuration. By tuning how much vCPU and memory Lambda and App Runner are allocated, you can boost performance wildly… for a price.
App Runner - 1 vCPU, 2GB memory, 100 concurrent connections per container, minimum 1 container, maximum 25
Step Functions and Direct Integrations - These services do not have configurations and cannot be tuned
The Results
To test each implementation fairly, I ran a series of 5 tests with various amounts of load and concurrency. I wanted to see how each service scaled and how performance was affected as it handled bursty traffic and scaling events.
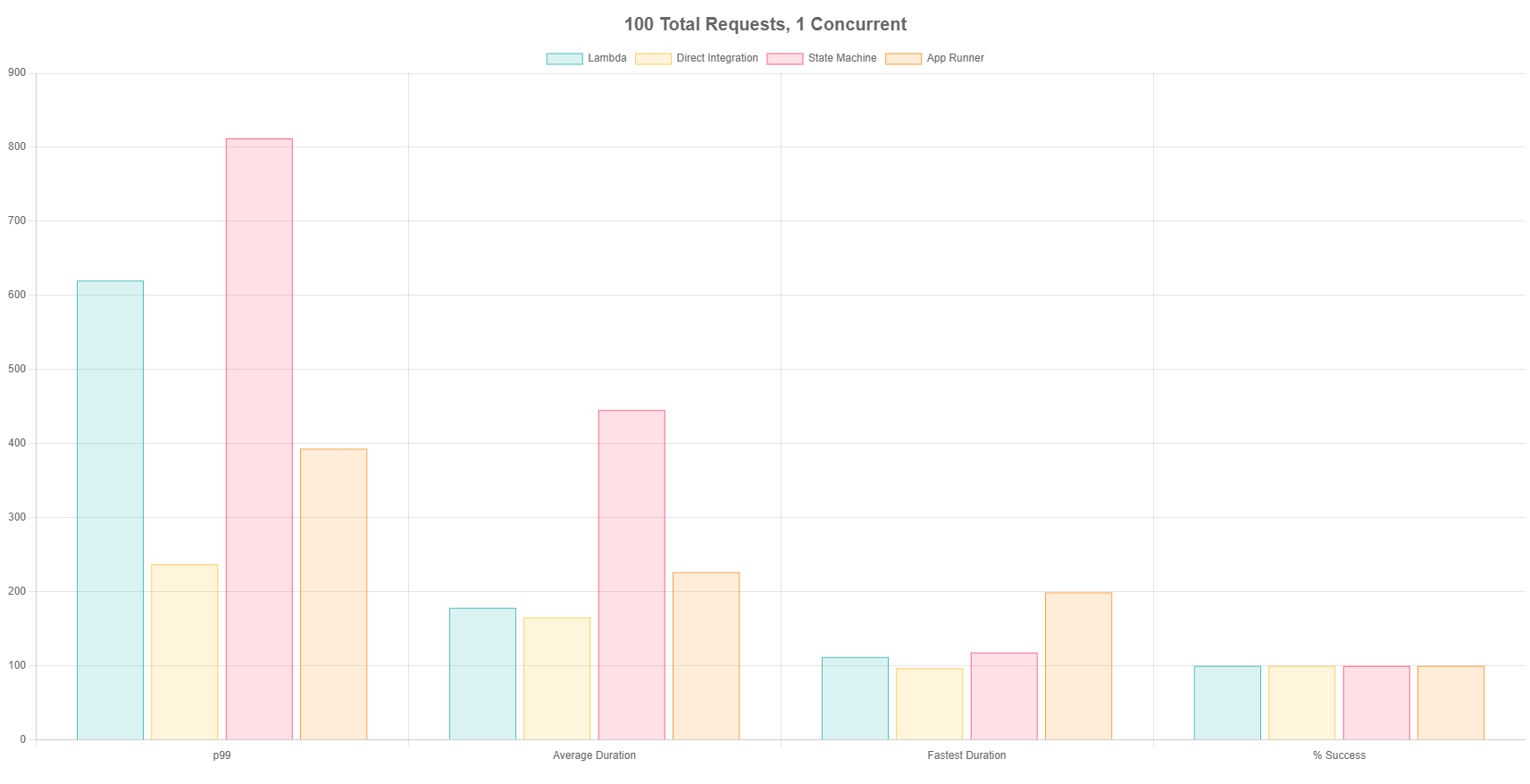
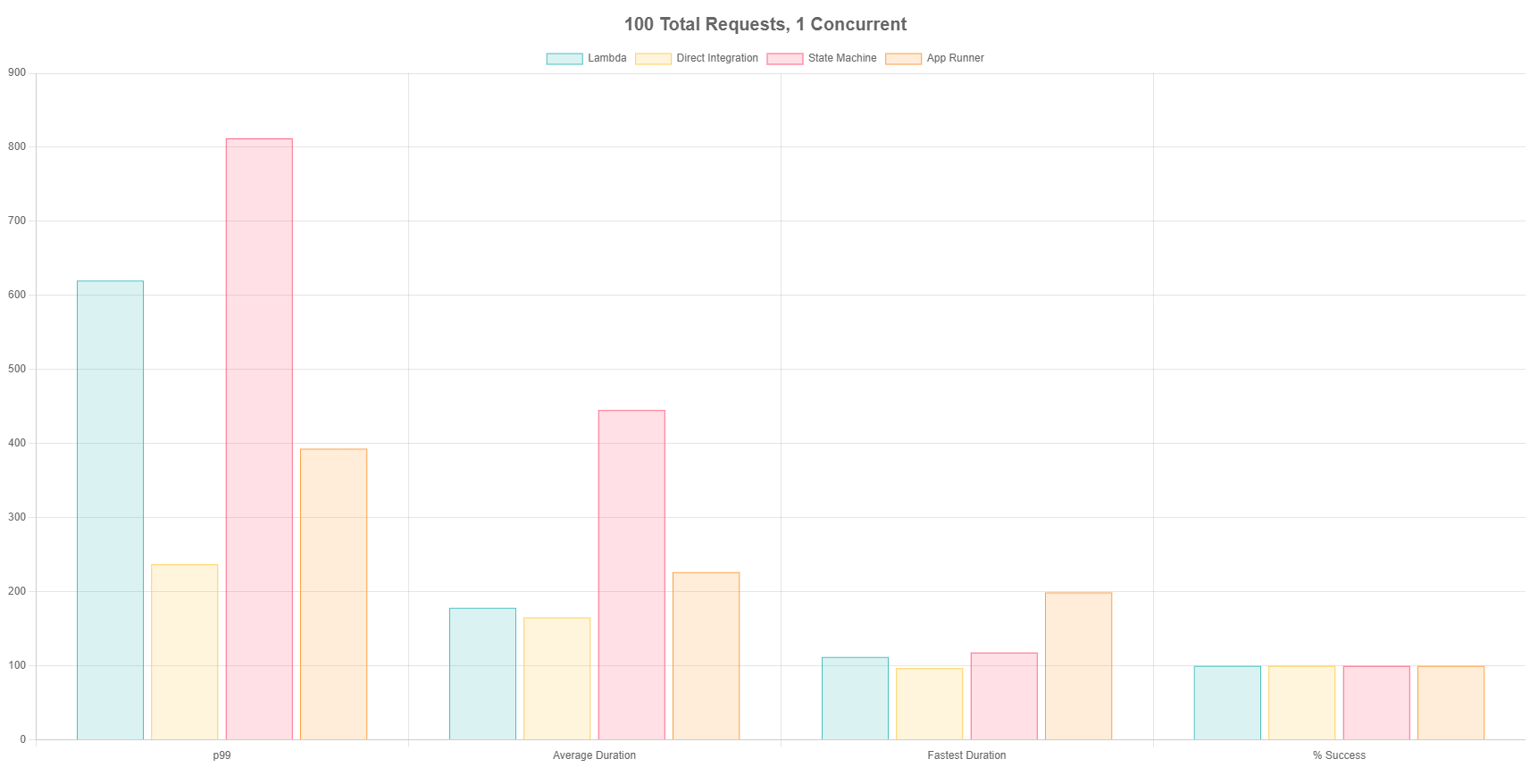
Test 1 - 100 Total Requests, 1 Concurrent
For the first test, I hit each endpoint 100 times with a maximum concurrency of 1. This means as soon as I got a response from a call, I’d fire off another one. This simulates a relatively small workload and exceeds most hobby projects.
Everything performs decently well at a small load. The direct integration performs the most consistently, with only 120ms difference between the fastest and slowest iteration. App Runner was the next most consistent, but slightly slower average duration. There was a 100% success rate across the board.
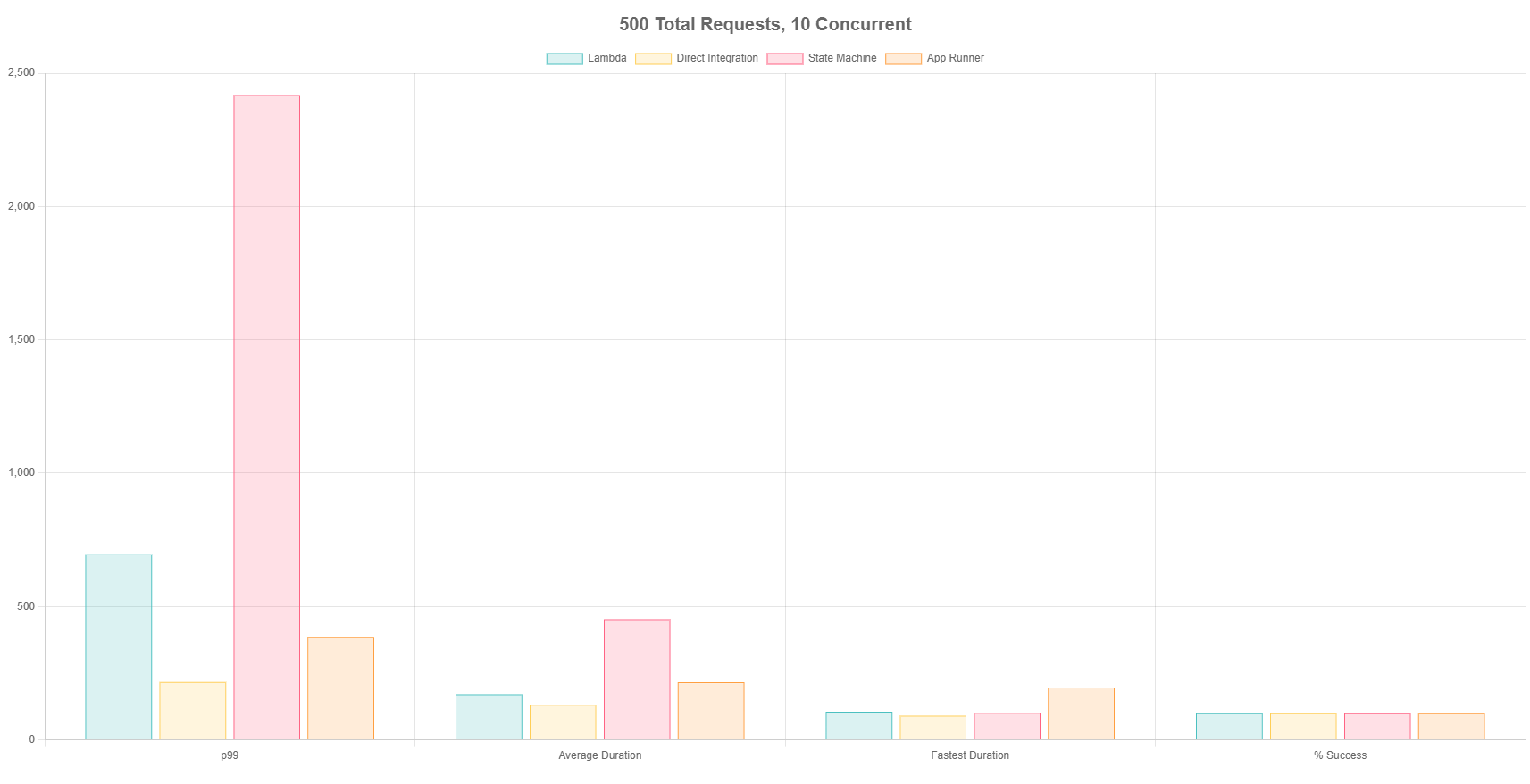
Test 2 - 500 Total Requests, 10 Concurrent
The next test ran a slightly heavier load, hitting each endpoint a total of 500 times with 10 requests going at all times.
All methods handled scaling events gracefully and did not throw any errors. The fastest call continues to be owned by the direct integration, followed closely by Step Functions then Lambda. App Runner was consistently slower both on average and for the fastest call.
The obvious call out here is the p99 duration for Step Functions. This is so much slower than the others because of the way Step Functions enqueues calls during scaling events. Rather than throwing a 429 when the service is too busy, it queues up the request and runs it when capacity is available. As a result, the p99 went out of control and was almost 5x slower than the second slowest. This is what brought the average duration down as well.
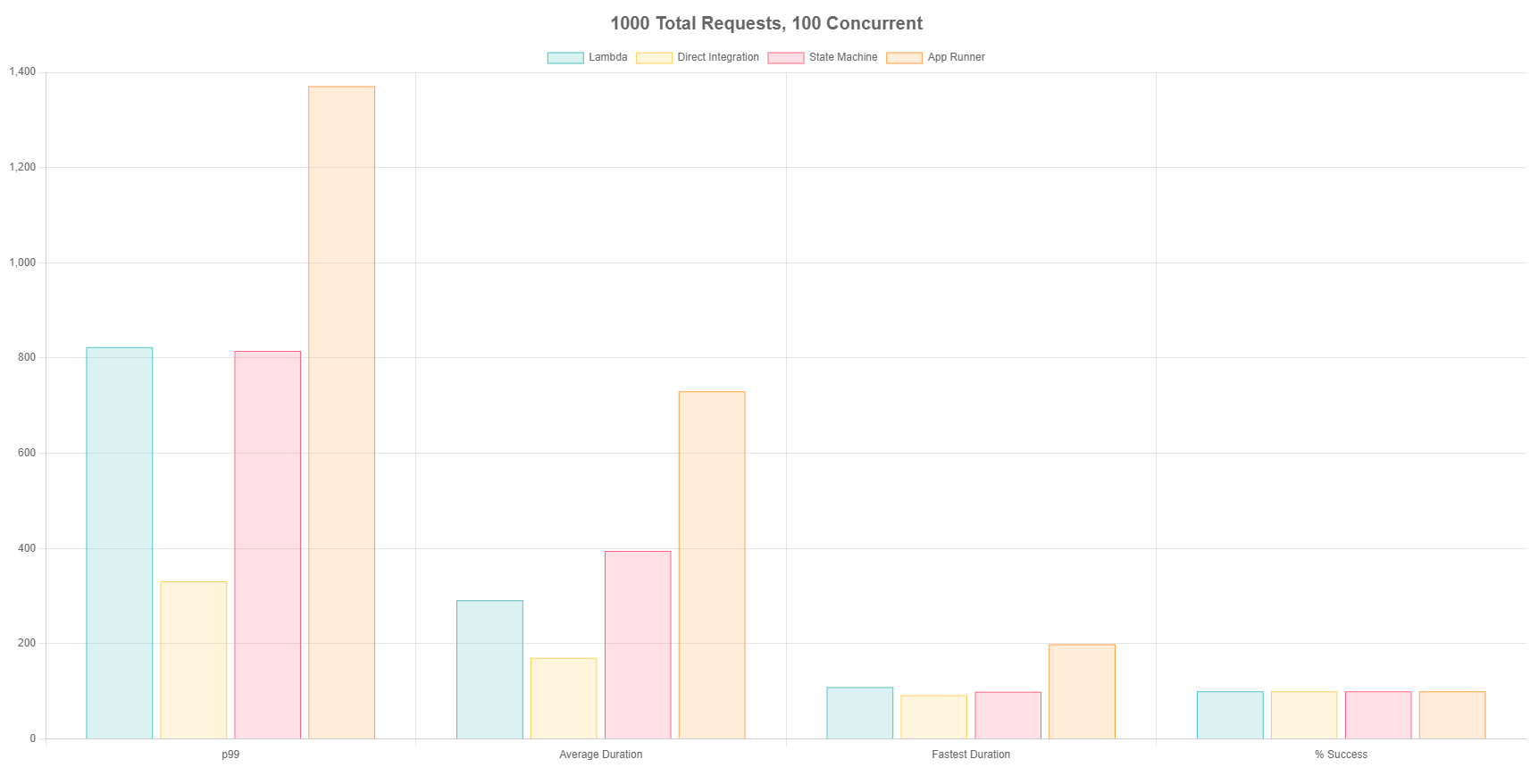
Test 3 - 1000 Total Requests, 100 Concurrent
Now we’re getting into some decent tests. Test 3 sent in 1,000 requests to each endpoint in batches of 100. This test was aimed to see how the services handle true traffic spikes.
This is where the results become interesting and I can merely speculate on these outcomes. We see App Runner really start to slow down with the load here as it begins to scale. You also see Lambda and Step Functions with roughly the same p99, but Lambda winning out on average duration. There were plenty of cold starts in this test, and it appears plenty of queued up Step Function runs as well.
We see good ol’ direct integrations continuing to perform faster and more consistent than any of the other methods.
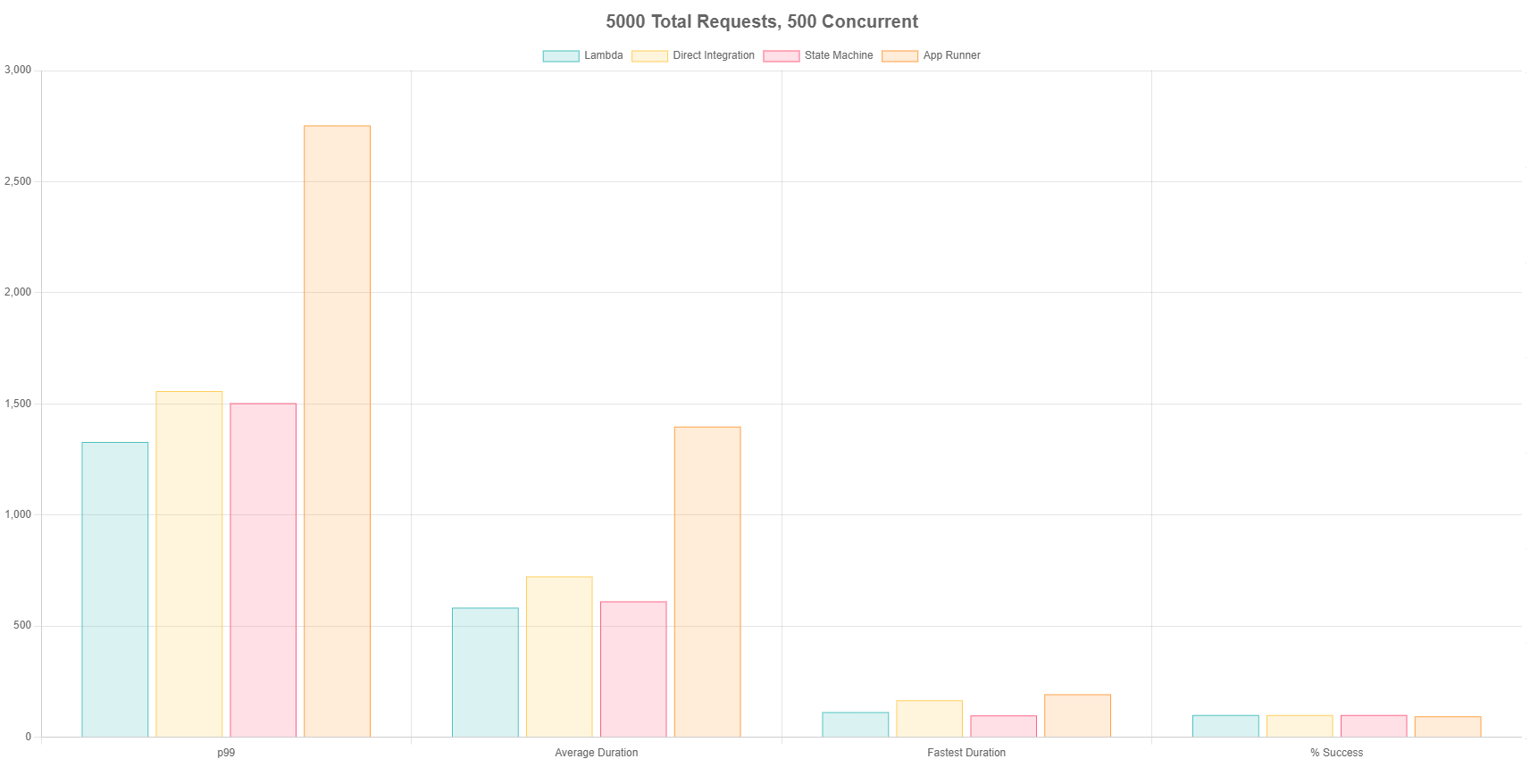
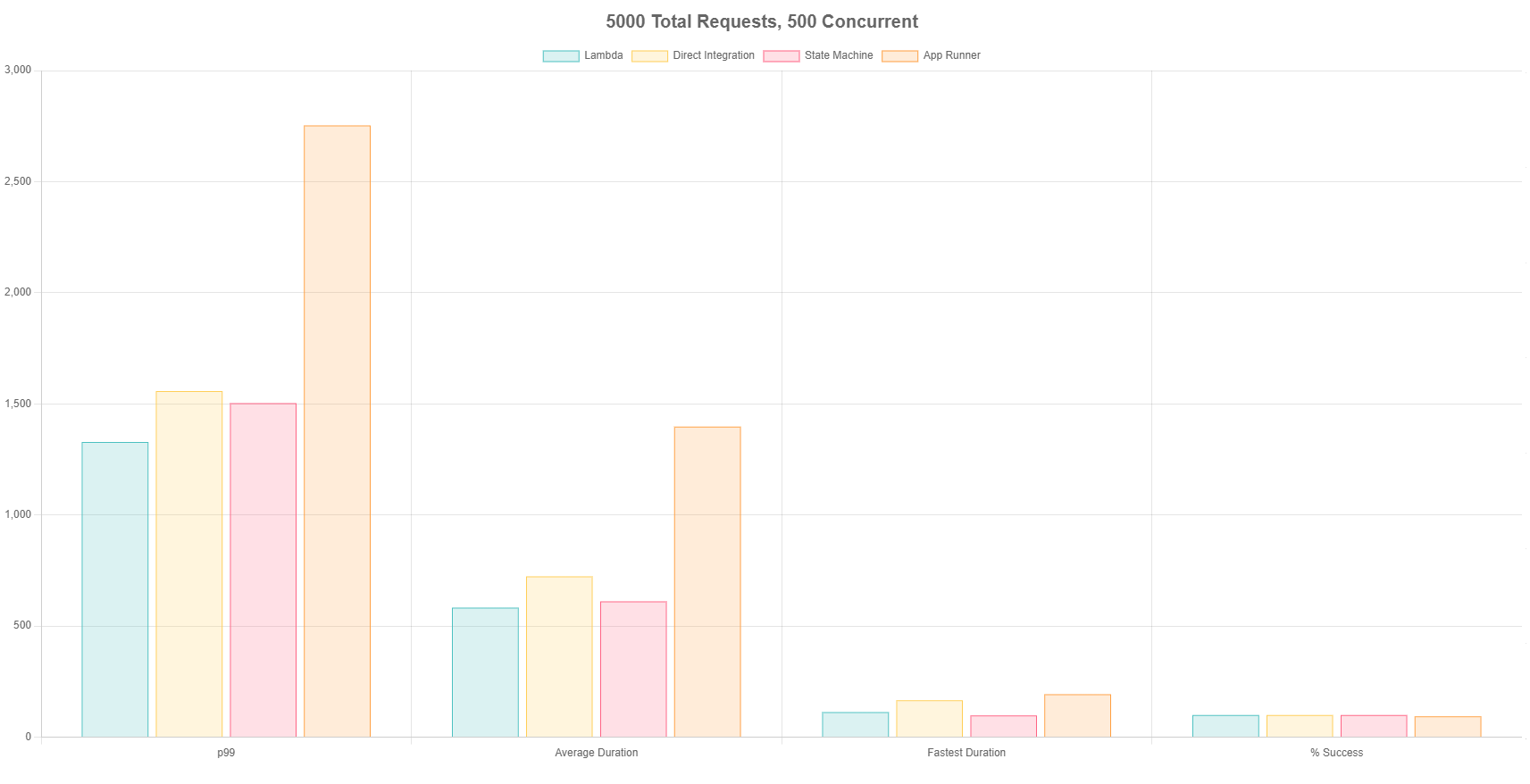
Test 4 - 5,000 Total Requests, 500 Concurrent
I really wanted to stress the services, so I upped the ante by going 5x from the last test. I sent in 5,000 requests to each endpoint with 500 concurrent calls. This would simulate a moderately heavy workload in an application, as it was resulting in roughly 1,000 TPS.
This was the first time I started seeing errors come back in the calls. App Runner began returning 429 (Too Many Requests) errors as it was scaling out. It was only about 5% of calls, but no other method had issues with scale.
This also was the first test where everything seemed fairly consistent across the board, no service seemed particularly better or worse than the other (with the exception of App Runner). Everything slowed down on average with this amount of load due to scaling events, but the fastest durations were consistent with what we had seen in the other tests.
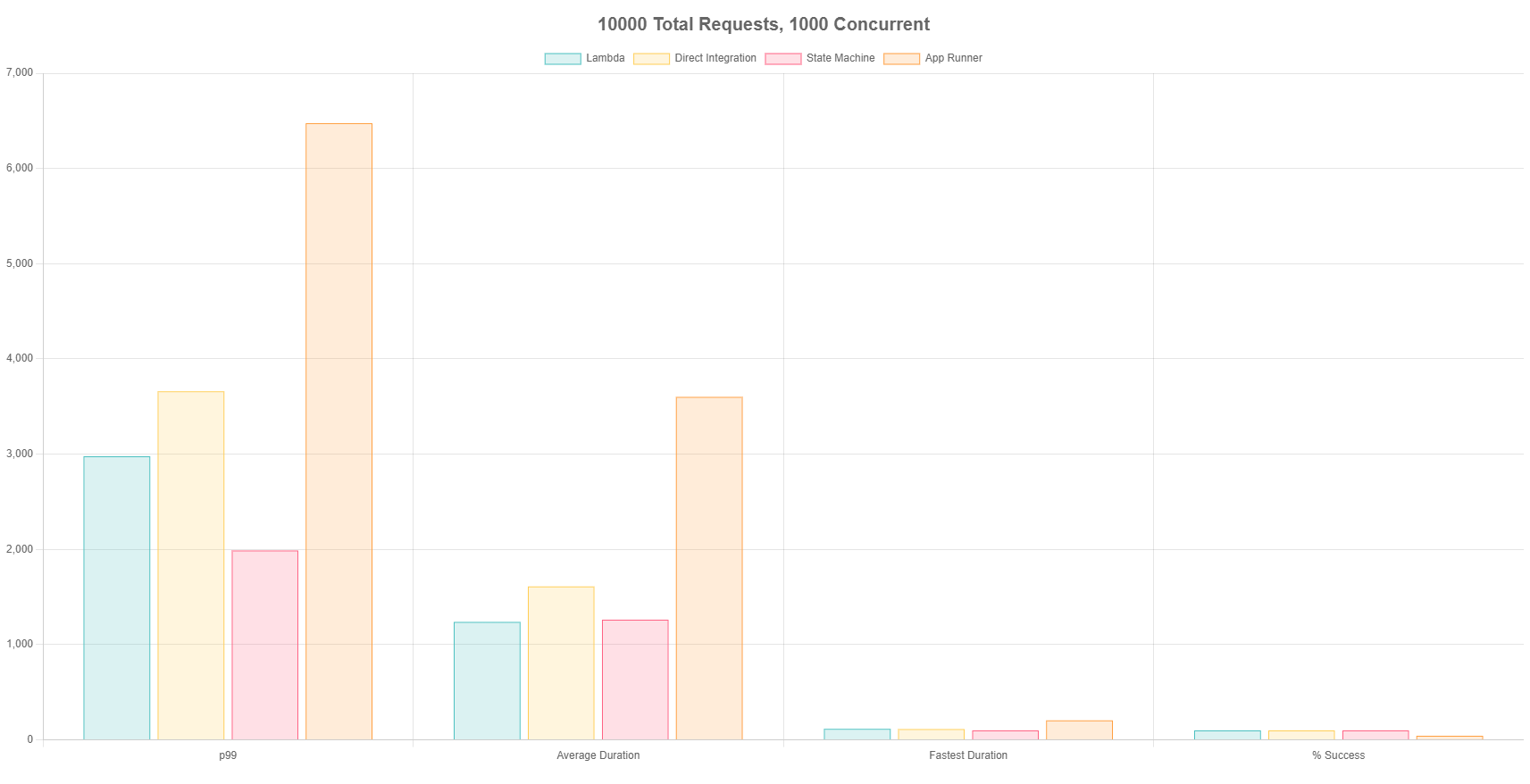
Test 5 - 10,000 Total Requests, 1000 Concurrent
In the last test, I wanted to push it to the max an AWS account could handle without upping service limits. I sent in 10,000 requests to each endpoint with 1,000 concurrent requests. This butted up against the service limits for Lambda concurrency and quite possibly for Step Function state transitions as well.
I began to receive 500 response codes from Lambda at this load. I tried to find the errors, but there were too many logs for me to dig through :grimacing_face:. I also received 429s from App Runner on 57% of the calls (yikes).
Errors aside, things seemed to perform linearly compared to the previous test. It was double the workload and I got back about double the p99 and average duration. This very likely could have been a limitation on the data side of things. It’s possible my dataset wasn’t sparse enough and I was beginning to get hot partitions and execution suffered as a result.
Conclusion
These were very interesting results and to be honest it is difficult to draw hard conclusions. When operating at scale, your best bet might be to push as much processing to asynchronous workflows as you can. Handle scaling events by hiding them.
The direct integration from API Gateway to DynamoDB seemed to perform the best at small to medium scale. It had the fastest tail latencies and was consistently faster on average to respond.
Step Functions and Lambda had interesting results. Lambda clearly seems to scale faster than Step Functions, but both perform at roughly the same speed on average.
App Runner was given an unfair disadvantage. The way I had it tuned was not up to the challenge. It’s a great service with tremendous value, but if you’re looking to use it for high performance in production, you’ll need to up the resources on it a bit.
If you want to try this out on your own, the full source code is available on GitHub. If you have any insights I might have missed from these results, please let me know - I’d love to make better sense of what we saw!
I hope this helps you when deciding on how to build your APIs. As always, take maintainability into consideration when balancing performance and cost. The longer it takes to troubleshoot an issue, the higher the cost!
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: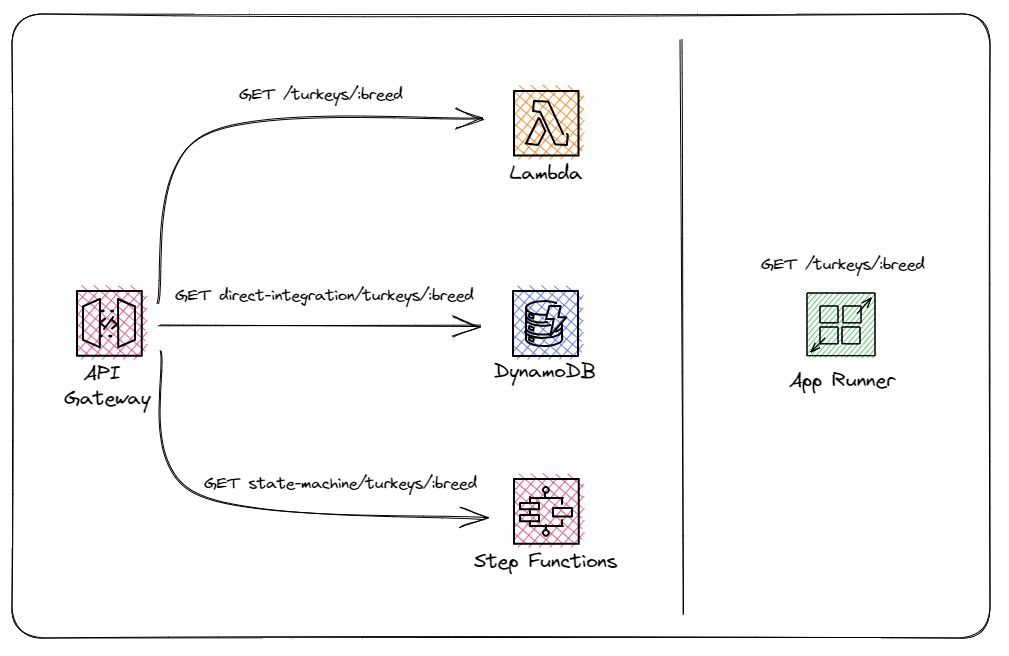

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}