Road to re:Invent Hackathon: How Not to Build a Serverless App
By Allen Helton23 December 2025
Listen to me read this!
I look forward to the first of December every year. Not because we’re squarely in the Christmas season, but because of AWS re:Invent. It’s always a highlight of my year professionally because I get to see a lot of people I interact with in the community in person. In many cases this is the only time of year I get to see them face to face. This year was extra special because I took part in the first-ever “road to re:Invent” hackathon, which put me and 49 other developers on a bus and drove us from LA to Vegas.
The drive is about 6 hours, and while we were on the bus - we got to code. As soon as we arrived in Vegas, the hackathon was over and we had one minute to present our solution to the judges. Honestly, condensing a presentation down into a minute was harder than the hackathon itself. We could give highlights, but not really show how the projects shine.
This was a shame, because the prompt was so funny! We had to build a product that solved a useless problem in a magnificently overcomplicated way. Props to the AWS team for coming up with this, it was a prompt that set a level playing field wide open for interpretation.
My mind works in mysterious ways, because as soon as I heard the prompt I jumped straight to “don’t count your chickens before they hatch,” which is an old idiom basically stating that you never know what will happen until it happens. I have a farm, so I decided to take that saying literally, because it is true, you never know how many eggs will hatch when a chicken starts to sit.
Since I only had one minute to talk about it at re:Invent, let’s cover what this project did in detail because it’s just as ridiculous as it is over-engineered. And available for you to try yourself in your AWS account!
Counting chickens before they hatch
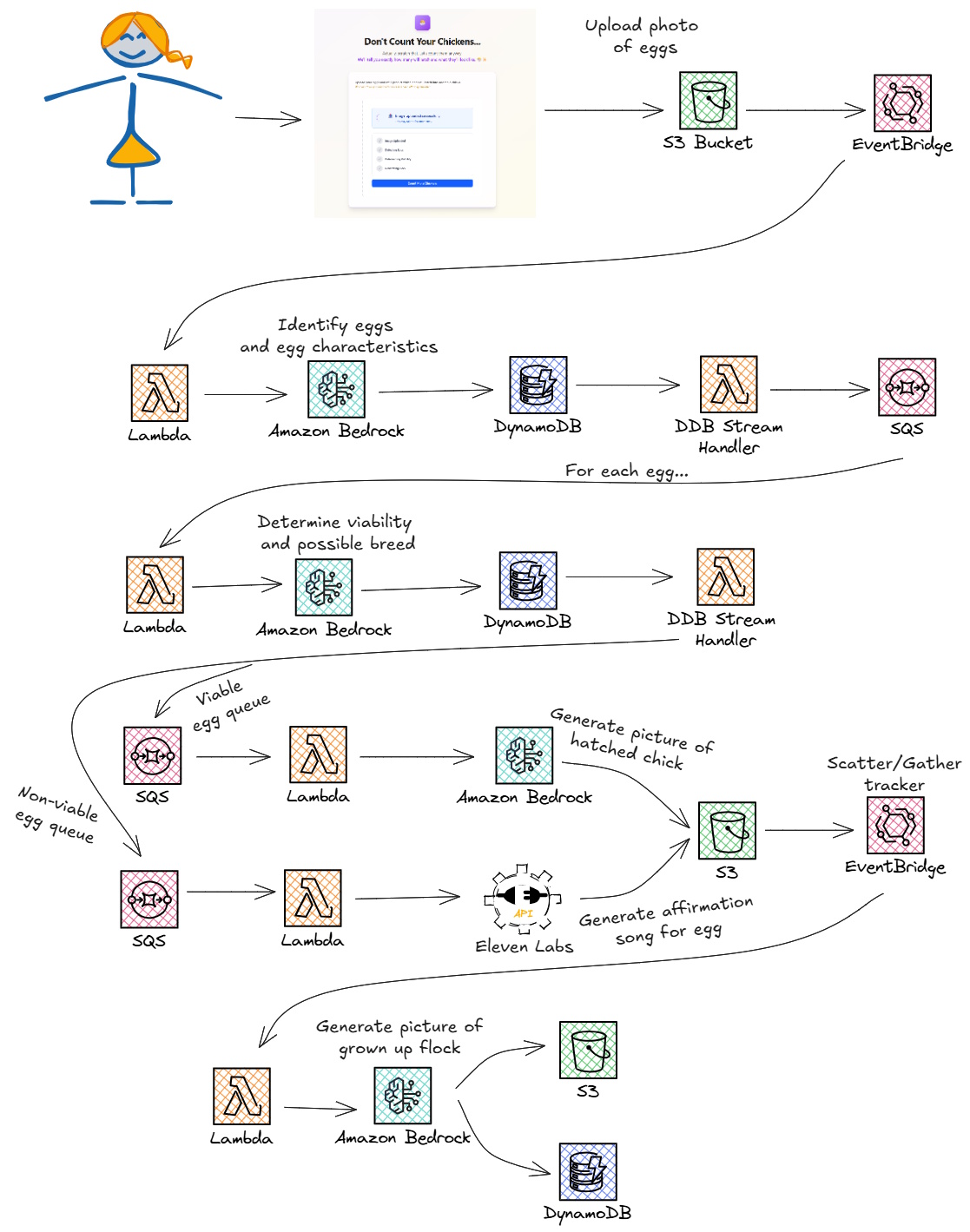
So what does this app do, exactly? First, the user uploads a picture of a clutch of eggs (a clutch is the word for a group of eggs) to the web site. Then AI takes the wheel.
As you can see, we took the “over-engineering” part of this hackathon seriously 😅
From end to end, we run five distinct workflows. We start with egg detection, move to viability analysis, generate some pictures of chicks 😉, create “words of affirmation” music, then wrap it all up with a future flock family photo! Pretty cool, right? And useless? And over-engineered? You bet it is!
Egg detection
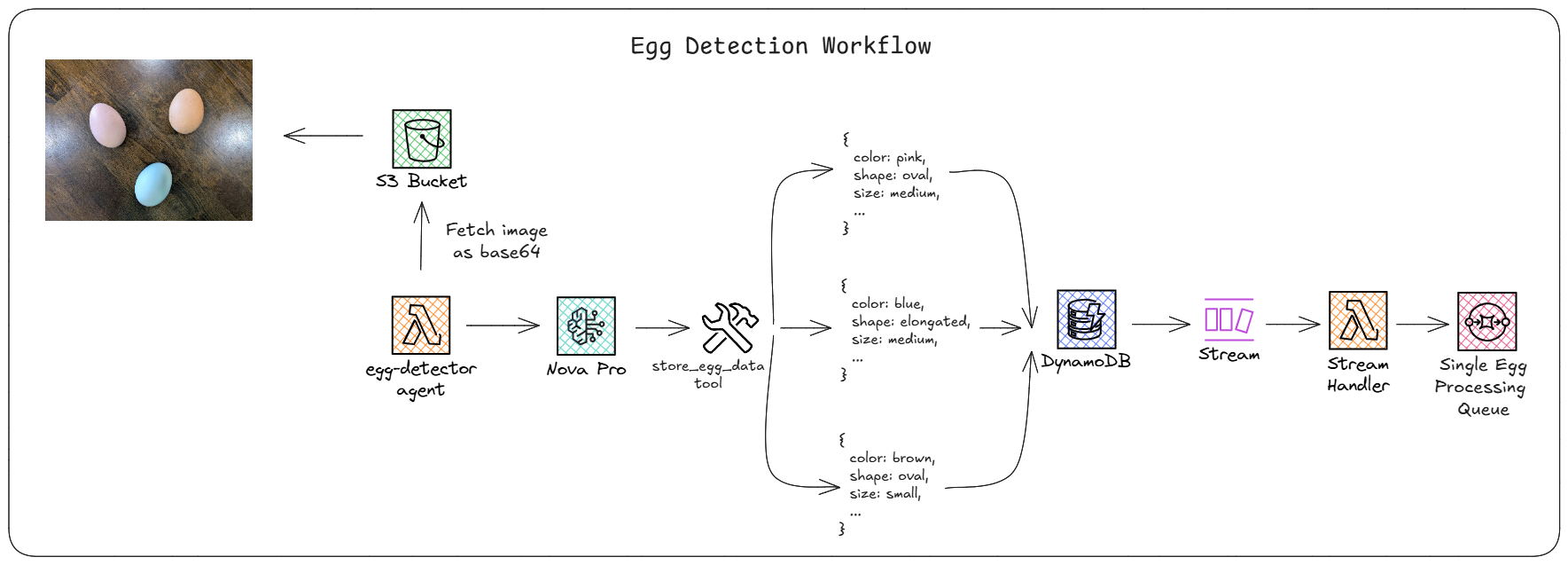
After an image is uploaded to S3, an EventBridge rule triggers a Lambda function that runs an AI agent using Nova Pro. This agent is given the image as input and is instructed to use the tool store_egg_data to log all the eggs it identifies in the picture along with information about the egg, like color, shape, size, texture, integrity, etc… We built this agent following the agent design principles Andres Moreno and I covered at length this year, meaning a strong system prompt that defined the work it was meant to do, and a minimal user prompt.
Instead of relying on the agent’s output and doing response validation, we forced it to use the store_egg_data tool and used the data directly out of DynamoDB in our workflow. We threw away the agent’s response because of the non-deterministic nature of agents. Using the tool meant we had guaranteed schema compatibility and our code was used to store it in the database the way we wanted.
Once saved to DynamoDB via the agent tool, a stream with batch size of 1 would trigger a Lambda function that formatted the data and dropped it into an SQS queue for further processing. The stream handler has a filter that looks specifically for inserts of records with a key prefix of EGG. This prevented recursive loops when we updated the data in later workflows.
At this point, the system fans out by processing each egg independently, then gathers everything back together later.
What we should have done
This workflow has too many moving parts, but on purpose. With the task of overengineering, I think we nailed it. But in a real-world scenario, we could have done things a little bit differently. Specifically, the stream to Lambda to SQS part of the workflow is completely unnecessary.
Typically you see this pattern for async entity processing when you need a buffer or throttle mechanism for downstream resources. But in our case, we’re handling 1-10 eggs at a time. We’re well beneath the threshold for buffering. Instead, I probably would have designed this to make the store_egg_data tool simply publish an EventBridge event that contains the egg data and created a rule that targets the next part of our workflow.
EventBridge publishing will automatically retry up to 185 times if it’s unable to deliver a message to a target. Beyond that, it will route the message to a dead letter queue for reprocessing. This works perfectly for our use case and is the better engineering decision for our app.
Determining egg viability
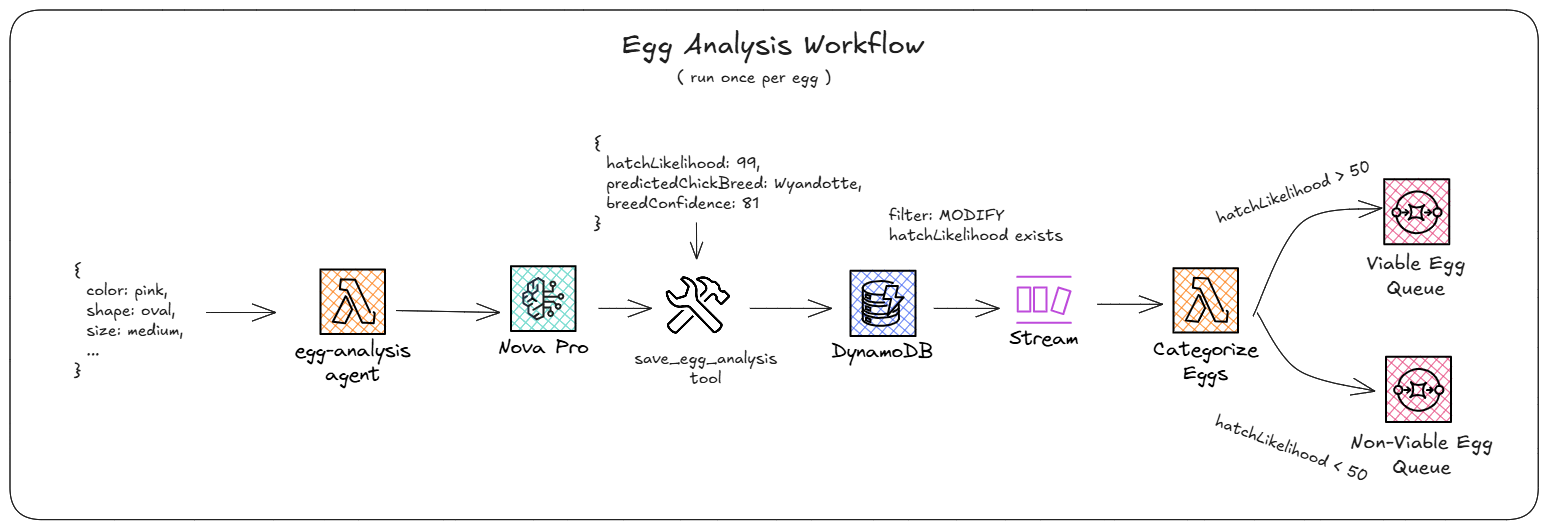
Now that we’ve identified all the eggs in the uploaded image, we have “scattered” execution in a scatter/gather pattern. For each egg, we run the egg viability workflow. This workflow uses another AI agent to determine two things: what breed of chicken will hatch out of the egg and how likely is it to hatch given the data we’ve collected.
Input starts with the JSON object from the SQS queue, which is mostly the schema straight from DynamoDB. This data blob is then used to build the system prompt for another AI agent tasked with identifying the chicken breed based on the color, size, and texture of the egg. It is also asked for a hatchLikelihood property (0-100 score on how likely it is to hatch) given the rest of the egg data. It saves both the breed and the hatch likelihood in a single save_egg_analysis tool call which updates the egg record in the DynamoDB.
Once again, we have a Lambda function attached to the DynamoDB stream, this time filtering on MODIFY egg records, specifically ones that did not have a hatchLikelihood property on the OldImage but do have one on the NewImage. This is a ridiculously overcomplicated filter to register an event handler. The Lambda function looked at the hatchLikelihood property and if it was less than 50, put it in the non-viable SQS queue. If it was 50 or greater, the data went into the viable SQS queue.
What we should have done
This is the first part of a scatter/gather pattern - an advanced architectural pattern. One way we typically see this pattern implemented is through orchestration, rather than choreography (like what my team implemented in the hackathon). Step Functions (and now Lambda Durable Functions) is a great way to orchestrate work through a known set of items. The takeaway here is to iterate through data with a known and controlled mechanism rather than through event-based choreography.
We could have simplified this workflow as well by batching eggs and passing batches to the AI agent instead of individually. This would have saved time and hundreds of tokens (and ultimately, cost!).
Finally, we run across the same overengineered pattern as the first workflow - DynamoDB streams to Lambda to a queue. There’s no need for this. Especially if we were using Step Functions or Durable Functions! We go to DynamoDB to update the egg state with our enriched data, but that easily could have been kept in the working memory of a workflow, no database needed! In an orchestrated workflow, you could have had a logical step to determine which path to take, viable or non-viable. That way we wouldn’t have to mess with queues.
But in the event you still went with choreography, EventBridge would have been the better call here instead of a Lambda function deciding on which queue to drop the data in. You could setup some content-based filtering rules that target the viable workflow when the hatchLikelihood is 50 or greater, or the non-viable workflow for less than 50.
Viable egg workflow
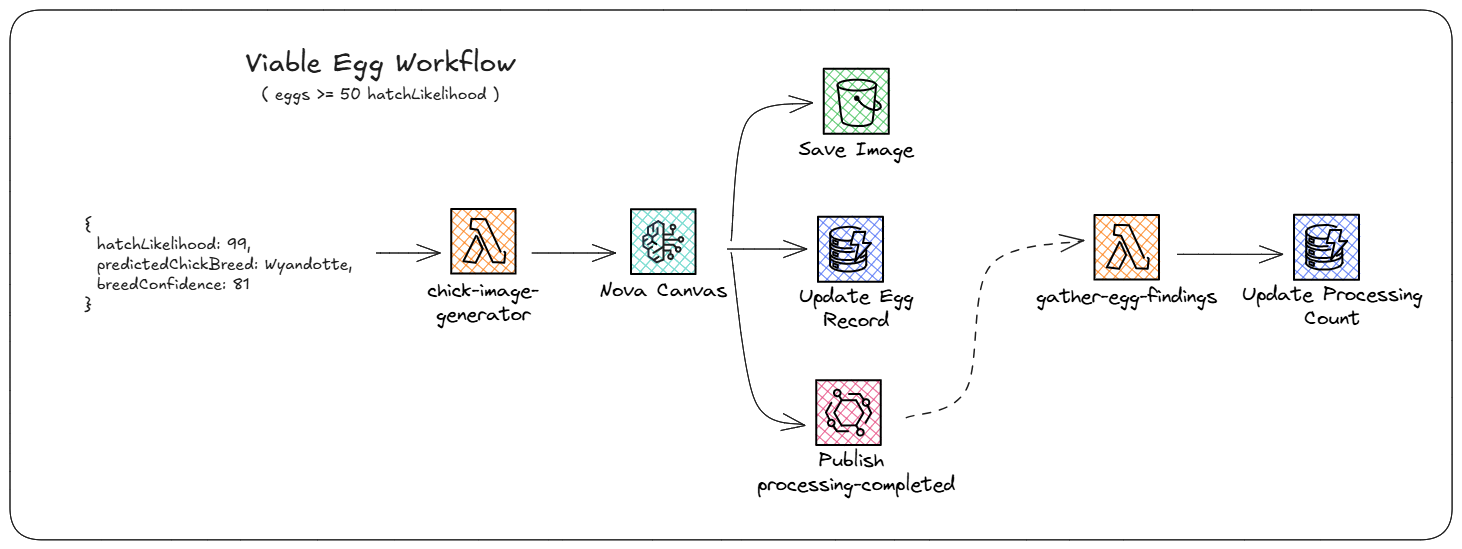
If the AI agent determined a specific egg had a 50% or higher likelihood to hatch, it ran through what we called the viable egg workflow. This workflow pulled from the viable SQS queue and triggered a Lambda function. The function called Nova Canvas to generate a realistic picture of what the baby chick would look like when the egg hatched. We then saved the generated image to S3 and updated the DynamoDB record with the object key of the image.
Then we publish an EventBridge event that targets a Lambda function. This function increments the processedCount attribute on our upload record as part of the “gather” side of the scatter/gather pattern. It increments the count until we reach the number of total eggs, at which point it fires another EventBridge event to kick off the finalization phase (more on this later).
What we should have done
Compared to the other workflows we’ve looked at so far, this one is much simpler. There’s not much new here that I’d change that we haven’t already spoken about. This one Lambda function is calling Bedrock, uploading an image to S3, updating data in DynamoDB, and publishing an event. It’s a lot of work for a single function. In a real-world scenario, this is probably a Step Function workflow using direct SDK invocations outside of Lambda. And if we were already orchestrating this in one giant workflow like we spoke about earlier, it’s a simple branch to add.
But because we opted for the more chaotic choreographed workflow, we have to track scatter/gather progress on our own - which adds additional fragility to the entire process. If you do choose to do this, don’t do what we did. Make sure you code for idempotency, because if your increment gets called too many times on accident, it will throw off your entire aggregation.
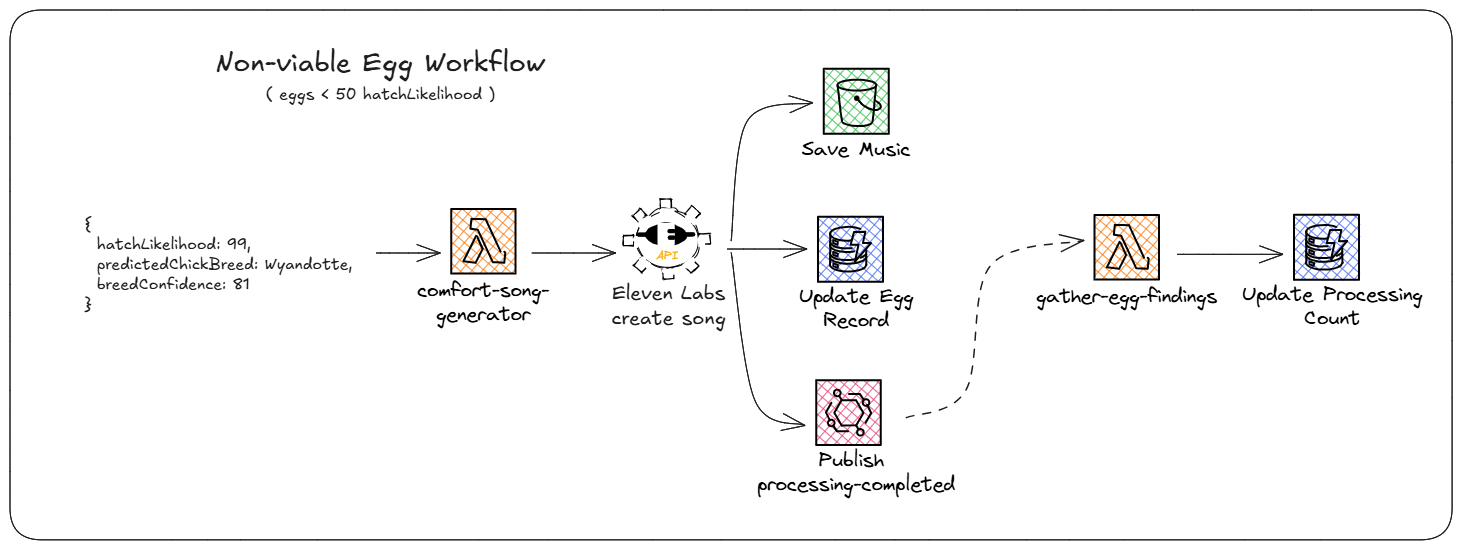
Non-viable egg workflow
We covered what happens when the agent thought an egg would hatch, but what about when it thinks an egg won’t hatch? As a farmer, I want all my eggs to hatch when a chicken is sitting. So this workflow is designed to encourage the egg into hatching via a song of affirmation. In a nod to the “solve a problem that doesn’t need solving” part of the hackathon prompt, our team decided to generate some music specific to the egg for the farmer to play and encourage the chick to continue developing.
To do this, we pull from the SQS queue and trigger a Lambda function. The function makes an HTTP call to the Eleven Labs music generator API, providing a prompt to an LLM hosted by Eleven Labs. This prompt asked for “an uplifting positive comfort song celebrating a ${eggColor} ${breed} egg. Use a warm, encouraging, and hopeful melody.” The API returned a song, and we’d save that into S3, update the egg record in DynamoDB, and publish the EventBridge event to signal the egg processing completed.
This workflow was almost identical to the viable egg workflow, but just traded out the created assets.
What we should have done
The same problems appear here as with the viable egg workflow. We should have done the same orchestrated path, but more importantly, we should have added safety mechanisms around the third-party API call. Eleven Labs has different rate and throughput limits than AWS services, so we should have been more careful around that. Always build safety around external dependencies.
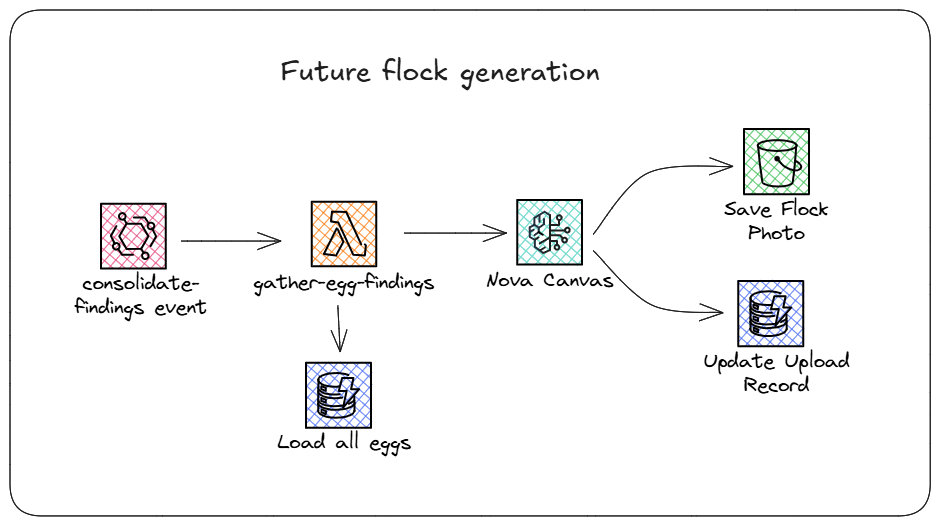
Future flock generation
Once all the eggs are processed, the gather-egg-findings Lambda function publishes an EventBridge event that kicks off the final workflow. The event targets a new Lambda function that loads all the eggs out of the database, filters the list to only the viable eggs, then generates a picture of what all the potential chickens would look like as adults. Since the model has extensive training data (including chicken breeds, apparently) it accurately draws what the hens look like. Ultimately, we get back a photo of a flock of chickens scratching in the grass, save that into S3, update the upload record status to complete, and are done with our workflow!
What we should have done
You know what I’m going to say. Yes, this part should have been a continuation of the orchestrated workflow. But getting down off my high horse, really we weren’t too bad with this workflow. We could have changed the DynamoDB data model so we didn’t need to load all the eggs and filter after loading. But really, this part was simple.
In a production scenario, I would have implemented real-time notifications here to notify the user interface the process completed. Given our time constraints, we designed the user interface to poll for updates every 5 seconds. While easy, it’s inefficient and wasteful. I’d recommend using something like Momento Topics or AppSync Events for quick push notifications.
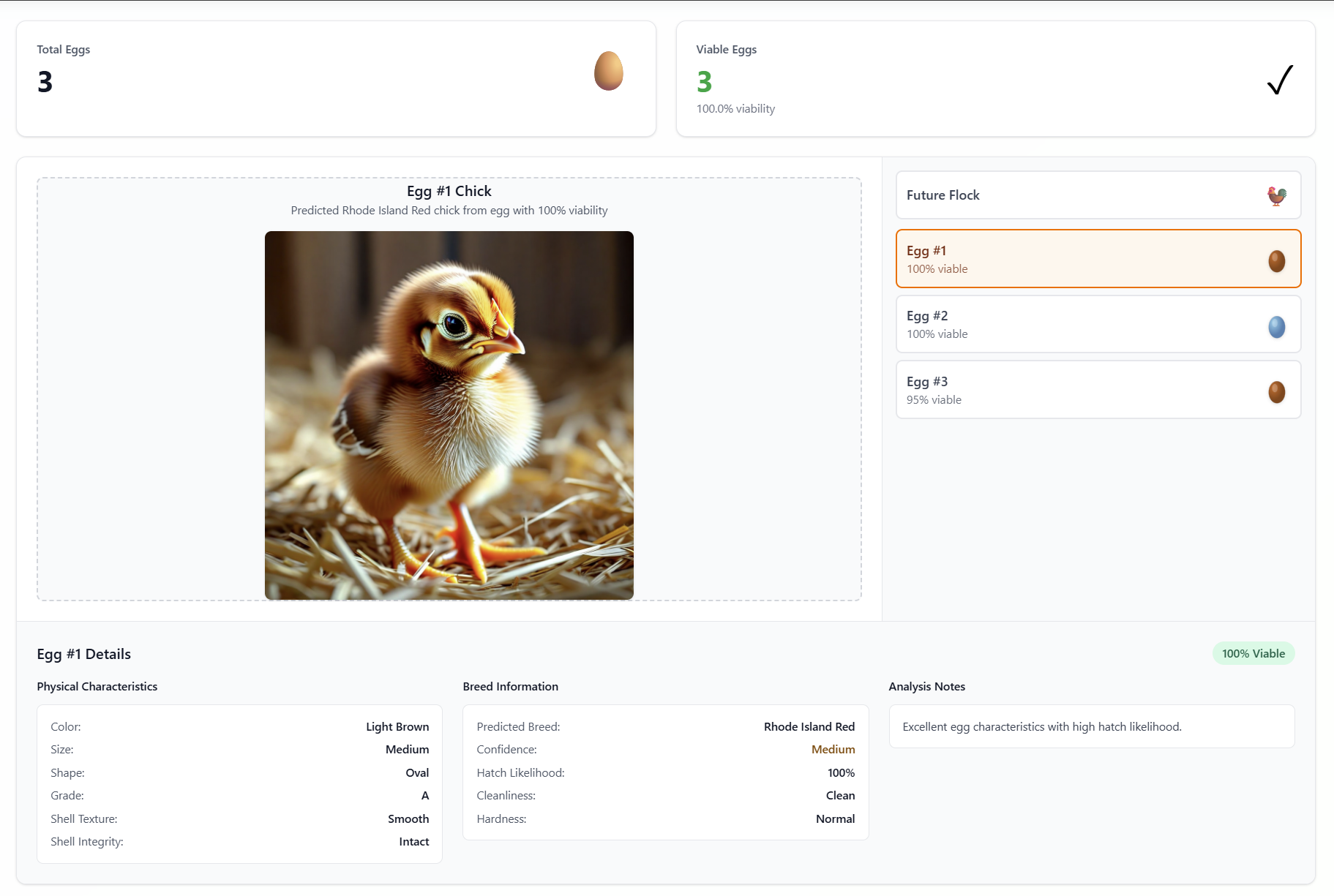
User interface
I have no regrets with this user interface. It is intentionally minimal as far as user interactions go. You upload a photo of some eggs and you wait. While you wait, the background polls a getStatus endpoint every 5 seconds. Each workflow updates the upload status, so we’re able to provide the user incremental updates so it shows something is happening. Once the API returns a completed status, the UI updates to a results view and presents the user with the overall breakdown of what’s going on with their eggs.
Overall thoughts
This whole thing was so much fun. Designing something so ridiculous and over-the-top was as much a rush as it was hilarious.
As soon as my team and I got on the bus, I sat them down and said “Listen, we can do anything we want but we HAVE to make it memorable,” and I feel we did just that. Everybody loves pictures of chickens and they’re such a fun topic of conversation.
Fun fact - Eric Johnson was the host representing both teams on our bus. There would be times he’d sneak over and listen as I was explaining the architecture of what we were building. I learned so much about building serverless systems from Eric, so having him over my shoulder as I was describing an intentionally bad setup made me sweat more than I’d like to admit 🤣
I had such a fun time with this hackathon and loved the opportunity to truly express my creativity. Thank you to the entire purple team! It’s a shame we didn’t win, but we learned a lot and had an experience of a lifetime.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: