Lately I’ve been working on a project that has significant meaning to me. It’s called the Good Roots Network, and it’s an application designed to connect local gardeners with people in their communities who need food. Growers list available produce, “gatherers” (social workers, non-profits, etc…) request it, and the system coordinates the full lifecycle from availability to pickup. It helps strike a balance in the community, too. When gardeners decide what to grow, it identifies gaps and suggests you grow something nobody else is to increase diversity and availability. Conceptually, it’s simple. Practically, it’s API-driven from the ground up. Roles, inventory state transitions, request validation, ownership transfer, notifications. All of it moves through contracts.
Like most devs these days, I moved fast at the start. I leaned heavily on Codex to build endpoints and handlers. Within a few days I had a working system. Authentication worked. Gardeners could declare what they’re growing. Listings could be created and updated. Gatherers could request produce and watch availability change in real time. From a product standpoint, it felt like real progress. Before I knew it, I had already blown through my GitHub backlog and had to come up with a completely new phase of development.
Before I continue, thank you to Postman for sponsoring this post. All opinions are my own.
The problem with unhinged velocity
As the API surface grew, small inconsistencies started to accumulate. Some routes weren’t as RESTful as I would have designed them by hand. Resource boundaries got blurry because endpoints were generated around use cases instead of being cleanly modeled around entities. Naming conventions drifted slightly across routes that should have shared the same pattern.
Technically it wasn’t broken, but that’s the part that really bothered me. When a system is generated unsupervised from use cases, it works for the cases it was built for. Problems show up later when you go to add features or extend it. REST is so much more than a stylistic preference. It’s also a bunch of smart constraints that make APIs predictable, intuitive, and composable. When your resource model is blurry, every new feature becomes a challenge to figure out what the API already does and what you actually need it to do.
The bigger issue was confidence. I had an OpenAPI specification, but I had no contract tests making sure the implementation aligned with it. This is something I’ve talked about for years and couldn’t believe I wasn’t practicing what I preach. I also had no end-to-end tests validating the full grower-to-gatherer lifecycle. And I had no reliable way to validate backward compatibility when I needed to make a change.
This is the problem of spec-last development. The spec becomes documentation instead of a contract. And documentation, by definition, is always slightly out of date 😉. When you treat your spec as anything but authoritative, it fails to live up to its full potential.
If the coding agent renamed a field in a response or adjusted a schema to better reflect the domain, there was no immediate signal telling me what would break downstream. When you’re afraid to evolve an API because you can’t guarantee it will still work, your development lifecycle is fragile. The agent helped me generate functionality fast. But it did not convince me it wasn’t building a house of cards.
So I opened Postman with a single objective: fix the gaps. But it wasn’t the Postman I recognized.
Postman is an API-focused IDE now
Formally known as “the new Postman,” this new version has completely changed both in appearance and in capabilities.
Instead of copy/pasting my API spec like I’ve done 100 times over the past several years, I can now create a new workspace pointed directly to a Git repository. Once connected, I’m presented with an all-too-familiar user interface, one that makes me feel at home like I’m in VSCode.
I can edit the source code directly, swap branches, open an integrated terminal, all things I could never do before in Postman. Which opens up many opportunities in its own right, but also got me thinking about a genuinely different pattern than I’ve operated in the past.
Instead of treating collections and specifications as assets that lived somewhere other than the codebase, they became part of it. They branched with features. They showed up in diffs. They moved through pull requests. They lived on my local filesystem right alongside the rest of the application. The whole thing felt less like opening a separate API client and more like opening another pane in my IDE.
And while you might be thinking to yourself “I’ve always exported my collections as JSON and stored them with the code,” this is different. The biggest reason API artifacts drift is that they live outside the feedback loops that keep code honest. Code gets reviewed, tested, and fails the build when it’s wrong. API specs, contract tests, and end-to-end tests historically, get none of that treatment because they are maintained in a separate app outside of where the code lives.
These assets are maintained by convention and good intentions, which is another way of saying they’re not really maintained at all. But putting them in Git and making them maintainable and runnable side-by-side with the code subjects them to the same forcing functions that keep everything else in the repo from becoming a mess.
Now, API changes are part of the feature branch. Checks for backwards compatibility, proper business workflow tests, and contract testing rolls squarely up into the definition of done alongside feature implementation. A huge departure from my “swivel chair” experience I lost when I went all-in on agentic development.
Building trustworthy tests
Years ago, I ran a team that had ridiculously good end-to-end tests. We spent lots of cycles making sure they correctly exercised real business use cases and made sure to maintain them as we made enhancements to the application. It took a lot of time, and it required extensive knowledge of the domain.
My problem with Good Roots Network is that it’s a solo project. Before I had someone dedicated to identifying, building, and monitoring these tests in Postman. I don’t have the capacity to repeat that.
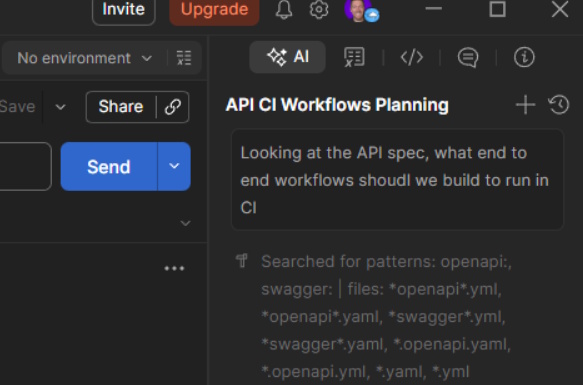
Agent Mode is exactly what it sounds like - an integrated AI agent (with user-selectable models) with workspace-level context, optimized for API development.
Workspace-level context now comes with access to the full source code. Exactly what I needed for the agent to quickly get up to speed on both capabilities and business knowledge. All it takes is a single, vague prompt with an intelligent model and I was off to the races.
As with all consumer-based applications, Good Roots Network revolves around flows, not isolated endpoints. A grower lists produce. A gatherer requests it. Inventory transitions correctly. Notifications reflect state changes. These behaviors in sequence are so much more important than whether any single route returns a 200. The lifecycle is the thing that needs to be tested. An endpoint that works perfectly in isolation can still be completely wrong in the context of a multi-step flow.
Even with my generic “what should we test” prompt, Agent Mode generated contract tests tied directly to the schema definitions and assembled end-to-end request sequences that reflected real state transitions.
That coordination is the 😙🤌 I’ve been looking for with API development. Something that can infer the business as well as I can, and meaningfully infer the workflows it needs to solve. It’s something I can update in my agents.md file as part of my definition of done, and more importantly - block deployments if the implementation doesn’t match the spec or if I break backward compatibility.
Local and CI, finally the same thing
Speaking of blocking deployments, another long-standing pain point in API development is environmental drift. Tests pass locally and fail in CI. Environment variables need to be updated. Assertions have to be rewritten to fit pipeline constraints.
The root cause is almost always the same: local and CI environments are built separately, maintained separately, and diverge quietly over time. In many instances, I never even setup tests locally. I’ve just lazily pushed a code change and hoped CI would catch any problems. The problem with this approach is that not only do I end up pushing far too many commits with the message fix api error, but it’s also not optimized for iteration. CI pipelines are optimized for repeatability, local dev is optimized for speed. Those goals don’t technically conflict, but when they use different toolchains, you end up with two systems that test the same thing kinda but not really.
With the new workflow, the same collections I ran locally became the tests executed in CI through the Postman CLI. No duplicated logic or translation step between environments. The validation I relied on while iterating in a feature branch was identical to the validation protecting the main branch. When there’s only one definition of the test, there’s only one thing that can go wrong.
With the consistent tests in place, I felt more and more comfortable introducing change in my hands-off agent environment.
The breaking change test
Because of my trust issues, I decided to test out my new development workflow with an intentional breaking change. I renamed a response field in the crop listing endpoint and ran the suite. Contract tests failed immediately. The failure pointed directly to the downstream impact, not just that something broke, but what broke and why.
This is what contract testing is actually for. Not catching bugs. Catching assumptions. Every consumer of an API has a set of implicit assumptions about what it returns, and those assumptions are invisible until they’re broken. My breaking change not only would have broken integrators (if I had any), but it also would have broken pages in the user interface. Contract tests make them explicit. When you rename a field, you’re not just changing a string in a schema. You’re breaking every consumer that built logic around the previous name. Seeing that surface immediately, in context, before it reaches main, prevents so many potential production incidents.
Where AI-generated APIs struggle
There’s a lot of discussion right now about how AI changes the way we build software. Most of it focuses on speed. How quickly you can scaffold a feature. How fast you can go from blank screen to something that runs. But there’s a much more substantial problem.
AI tools are very good at building endpoints. They are much less opinionated about building systems.
When I let Codex chew through my backlog, what I got back was impressive when you look at the work that was done issue by issue. Each route handled its immediate use case. Each handler returned the shape it needed to return. But APIs are composed of many endpoints. They live in ecosystems. They accumulate consumers.
The faster you generate endpoints, the more surface area you create that needs to be maintained, observed, and continuously checked for backward compatibility. And if you’re not keeping up with that in the excitement of completing your backlog, well, that’s where things get fragile.
A single endpoint that works perfectly for today’s use case can undermine the long-term shape of the API if it doesn’t respect resource boundaries, naming conventions, and predictable constraints. And once consumers build on top of those assumptions, changing them becomes expensive, if not impossible.
In other words, generation is a moment. Maintenance is a lifetime.
APIs are more important than ever in the age of AI
If AI agents are going to consume APIs directly, then APIs are no longer mere integration points between services. They are interfaces for autonomous systems.
Agents don’t rely on tribal knowledge. They can’t. They rely on structure. Predictable resource models. Stable schemas. Explicit contracts. When you don’t have that, automation becomes brittle.
What changed for me while working on Good Roots Network was not just having better tests. It was having the API lifecycle treated as a first-class concern. Specs lived in Git. Contract tests blocked merges. End-to-end flows validated real business behavior. Local and CI used the same definitions.
Walking away from my first experience with the new postman left me with an astonishing amount of confidence.
Confidence that when I rename a field, I know exactly what I’m breaking. Confidence that my spec is authoritative, not aspirational. Confidence that the agent building features is operating within guardrails instead of on a blank canvas.
In the era of AI-assisted development, APIs are more important than they’ve ever been. They are the stable component that everything else depends on. Getting them right isn’t about stylistic preference or personal pride in design. It’s about making sure the systems we’re increasingly delegating work to can rely on something solid.
I went into Postman to fix a testing gap, and I came out realizing that the real value wasn’t faster generation. It was durable structure.
If you’re building quickly with AI, that structure keeps velocity from turning into entropy. And that’s a trade worth making at any stage of a project.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.

 Share on:
Share on: