
Application development
 Share on:
Share on:
My ChatGPT Workout Generator Just Got Better
Back in February, I wrote about a fitness app I built using ChatGPT. It wasn’t an app so much as it was a daily email with a randomly generated workout. And it wasn’t ChatGPT, it was one of the other AI models available from OpenAI (ChatGPT wasn’t available yet).
As a developer, I can’t leave well enough alone, so I decided to make some updates to the project. The original purpose was to take workout creation off my plate and give me something easy to follow during my morning workouts. The original iteration worked ok, but I would routinely get unrelated exercises thrown into the workout, like barbell squats on arm day. I also found myself coming up with a relevant warmup and cooldown every day.
So it helped some, but not as much as ideally wanted. I wanted better workouts, a related warmup/cooldown, and to share with my friends a little easier. It was time for an iteration.
Moving To The Real ChatGPT
When I built the original version, I genuinely thought I was using ChatGPT. I was under the false assumption that any model coming from OpenAI was, in fact, ChatGPT. As many of you told me, it is not.
So I upgraded the model from text-davinci-003 to gpt-3.5-turbo. But the model change required a different endpoint that accepted different inputs. So I updated the Lambda function that made the query and discovered this new endpoint provided a way to add context to my queries. I could pass in a system configuration that tells ChatGPT how to approach the prompt. I could also provide it an array of messages to simulate a conversation, exactly like when you use ChatGPT in a browser.
The introduction of the chat concept was intriguing. I had originally incorporated my ChatGPT function in a Step Function workflow, which has a relatively low maximum data size. So passing around a collection of questions and answers between states didn’t seem like a great idea. With this in mind, I decided to store the conversation history in a cache using the Node.js Momento cache client.
Below is an illustration of how the updated Lambda function uses Momento and OpenAI to hold a conversation. It even retains context across execution environments!
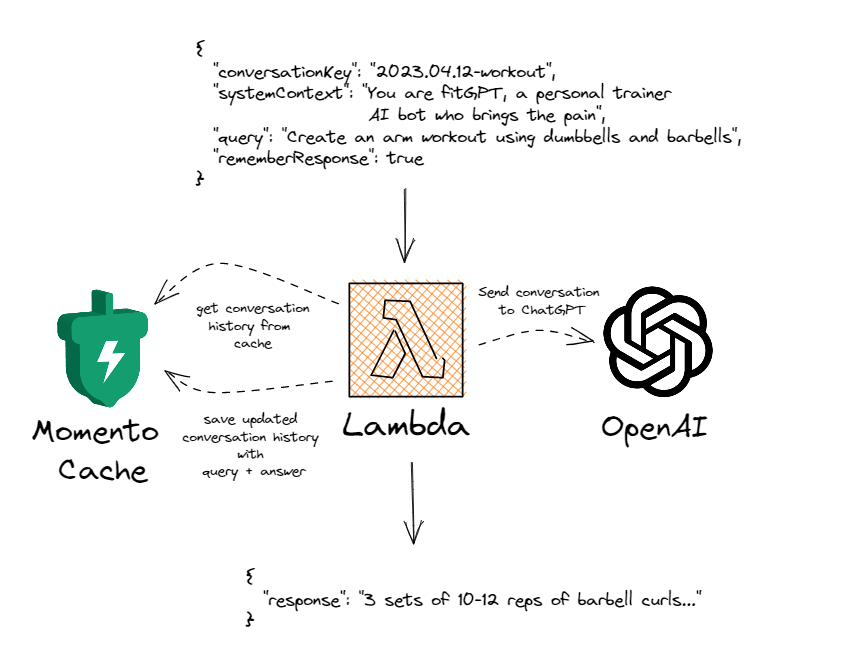
The entire conversation is stored in a cache for an hour, then expires automatically. All messages are saved chronologically in a list, with each subsequent call adding the query and response to the conversation history (as long as the rememberResponse flag is provided and set to true).
This means in the implementation of my Step Function workflow, I don’t have to keep a record of the chat history, all I need to do is pass around a conversationKey and the function handles the rest of it.
Creating a Tailored Warm-up and Cooldown
Now that I was able to query ChatGPT with context, I unlocked the ability to get a warmup and cooldown specific to the generated workout. My first query to ChatGPT asks it to build a workout for a specific muscle group using some of the equipment I have available. The next couple of queries build on that answer to enrich my workout with relevant exercises.
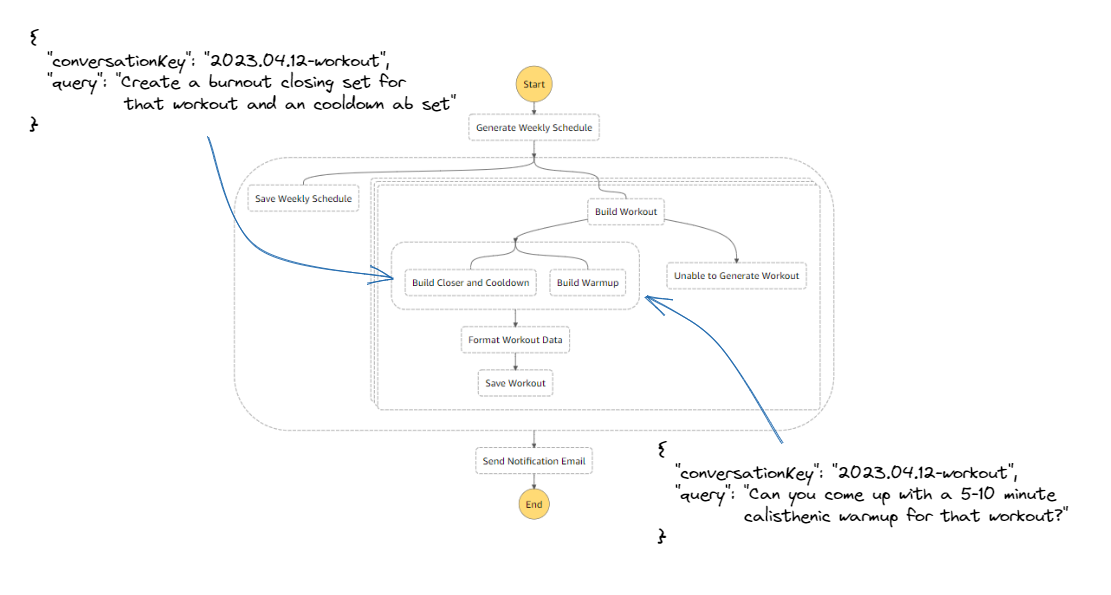
By passing in "conversationKey": "2023.04.12-workout" to the function, the system context and generated workout are automatically loaded and provided in the subsequent queries. Pretty neat!
The result of this brief conversation with ChatGPT is an intensely focused warmup, main set, closing “burnout” set, and ab workout all targeting the same muscle group. Plus, it’s personalized to use only the training equipment I have available in my home gym, and selects which equipment to use on a weighted, random scale. To say my workouts have gone from ok to good to outstanding would be an understatement.
Sharing the Fruits of My Labor
The first version of this project sent me an email every day at 7 pm to let me know what the workout was going to be the following day. This works great when I’m the only person doing the workout, but I have some friends that exercise with me every week that wanted to know the workout ahead of time too. I easily could have added them to the distribution list or created a rule in my email to auto-forward, but that doesn’t scale well.
If more people wanted to join me or someone stops attending, I would have to update the list. I don’t want another list to maintain. So I decided the self-service route was the best way to go and built a webpage to display the workout of the day. Now I can point people at a url instead of updating an email list. Plus, it also gives me a chance to share my solution with the community, which is one of the main drivers for all my projects.
I’ve been practicing with NextJS lately to build my UI skills, so I took this as an opportunity to learn some best practices. But there was a problem - I wanted to host this under Ready, Set, Cloud. My site is built on Hugo and Amplify and doesn’t use NextJS.
I poked around in the Amplify console a bit and discovered you can easily create a completely new project under a subdomain. This allows me to keep the main blog separate from the fitness app, but still have them branded the same.
With a little bit of CSS work, I was able to make the fitness app look and feel like it has always been a part of Ready, Set, Cloud. As someone who has focused the majority of their career on the back end, this was probably the most satisfying part of the project.
I hooked the UI up to a new API I built to access the workout of the day. You can hit GET https://api.readysetcloud.io/fitness/workouts to get the workout for today. If you’re looking for a specific date, you can pass in a query string parameter to get it: GET https://api.readysetcloud.io/fitness/workouts?date=2023-04-01.
What’s Next?
This has quickly become a passion project of mine. I originally wanted a quick automation to take some mental stress off me in the mornings, but this has quickly turned into something more. It’s an opportunity for me to learn, put my serverless skills to practice, and contribute something meaningful to the community.
So, what’s next? All my workouts are archived, so I will be making them available and searchable in the upcoming future. If you need a list of arm workouts or want a browse through some circuit workouts, just search the archive.
I also plan to add login functionality to allow users to personalize their own equipment and workouts. After that, I’ll start to add satisfaction ratings to help tune the generated AI workouts even more based on your preferences.
This is open-source! If any of it excites you and you want to contribute, please check it out on GitHub! Feel free to fork it or open up a pull request.
If you want to take a look at the daily workout, you can find it at fitness.readysetcloud.io. As with all software, it’s not perfect. You might see something in there that looks a little buggy - and it probably is! Over time we’ll get those ironed out and polished.
Thanks for following along! Let me know if you have feature recommendations or questions.
Happy coding!
Related posts


Previous
Are Serverless Services Worth It?
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.