
Application development

Is Disaster Recovery Worth It In Serverless Applications?
Disasters are one of those things that you think “that will never happen to me”. The moment it does happen to you and you don’t have a plan, you think “why me?”
I was sitting in an all-day manager meeting last year, actively participating in conversation in prep for 2022. I got a tap on the shoulder and someone asked “hey, is your app down?”
To which I laughed and said “the only way it can go down is if an AWS region goes down.”
About 30 seconds later I received an email from AWS saying they were having some internal networking issues region-wide where my app was deployed.
I immediately start sweating as I tried to login to my app and am faced with a 502 Bad Gateway. My boss and my boss’s boss were in the room with me and asked what the plan was to get it back up and running. I was left stammering because there was no plan. Outages like this didn’t happen in the serverless space.
So I had to wait. Wait for AWS to figure out what was going on while I sat there and refreshed my app over and over again.
It sucked.
Or did it?
Disaster Recovery vs High Availability
People often think disaster recovery and high availability are the same thing. In fact, many people don’t even know the phrase high availability because they think that is what disaster recovery is.
I am here today to tell you they are not the same thing.
Disaster recovery is the ability to get your system stable after a significant event. Significant events could be things like natural disasters (tornadoes or earthquakes), physical disasters (building fire or flooding in server room), or technology disasters (hacked or ransomware).
High availability is the ability of your system to stay up and running in an event with no downtime. This is what we tend to think of when we think of disasters. How robust is our solution and how quickly can we respond in the event that a disaster does happen?
You can see how these two terms could be confused for the same thing. They go hand in hand when it comes to user satisfaction.
In an ideal world, your end users would never know if a disaster occurred.
Let’s talk about two main focuses with disaster recovery, Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
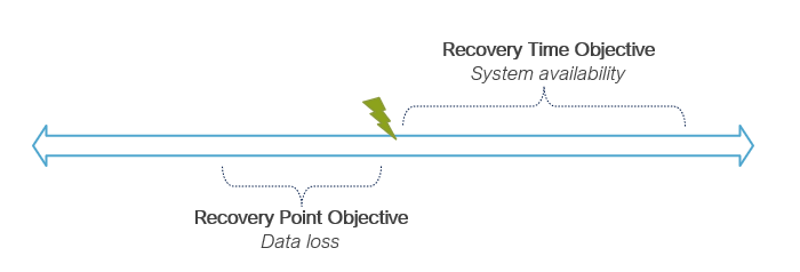
How RTO and RPO play into disaster recovery.
RTO is the amount of time it takes to get your system operational after a disaster. It maps directly to the availability of your application. If you have a plan in place to failover, your RTO is how quickly can you execute that plan to get the system functional again.
RPO is the point in time when you get your data back prior to the disaster. If the disaster results in you restoring your database from a backup, your RPO will be the time when the snapshot was taken.
So high availability is only half of the equation when it comes to disaster recovery. Both are equally important and if you miss your RTO/RPO you might fall out of your service-level agreement (SLA) and start owing your customers some money.
Serverless Freebies
When you opt to go serverless, you gain several benefits immediately when it comes to availability.
Serverless services like Lambda, API Gateway, SQS, SNS, and EventBridge all automatically span across all availability zones in a given region. This means you don’t have to worry about spinning up multiple instances in a multi-AZ architecture because AWS handles it for you.
You get high availability and automatic redundancy within a single region out of the box. Load-balanced, scaled architecture is part of the managed service, so you don’t have to worry about hitting your RTO.
When you’re using a database like DynamoDB, you get the high availability but you also have the option to turn on Point in Time Recovery (PITR). PITR allows you to restore your database with granularity down to the second for the past 35 days.
This means when it comes to your database, your RPO could be as small as 1 second. Once again, this frees you from worrying about hitting your recovery objectives because AWS is handling it for you.
So out-of-the-box, serverless applications provide us with high availability in a single region and an RPO of a matter of seconds.
Multi-Region Serverless Applications
If your application has a zero tolerance for downtime, like an emergency computer-aided dispatch (CAD) system, you will need to explore a multi-region application.
In the rare event that AWS has an entire region outage, your application has to automatically respond and failover to another region that is ready to go. Often called an active-active failover strategy, they end up running for dirt-cheap in the serverless world.
Since serverless has the pricing model of pay for what you use, having your serverless resources like Lambda functions and API Gateways deployed in a redundant region costs you no money. Where additional cost comes into play is getting your data into your failover region.
You can implement DynamoDB global tables to replicate data to your failover region. You pay for the write requests for the replication, storage, and data transfer costs. Let’s take an example: if your application consumes 25GB of storage with 15 million records in a month, then your cost to use global tables per month would be an additional:
25 x $.09 (data transfer cost per GB) + 15 x $1.875 (replicated write cost per million units) + 25 x $.25 (GB-month storage) = $36.63
Not a bad cost for the amount of reliability you get by going multi-region.
Another regional replication is S3 two-way cross-region replication. This enables you to replicate any documents added to an S3 bucket across region. If this is enabled, a document could be added in either region and be made available to the other region.
Replication for S3 documents incurs additional costs for storage, replication PUT requests, and data transfer out. If our application consumed 1 million documents for a total capacity of 5TB, then the additional replication costs would be:
5000 x $.023 (GB-month storage) + 1000 x $.005 (PUT request per 1000 requests) + 5000 x $.09 (GB data transfer out) = $615
Again, not a significant amount of additional cost when you’re talking about virtually eliminating your downtime in the event of a regional outage.
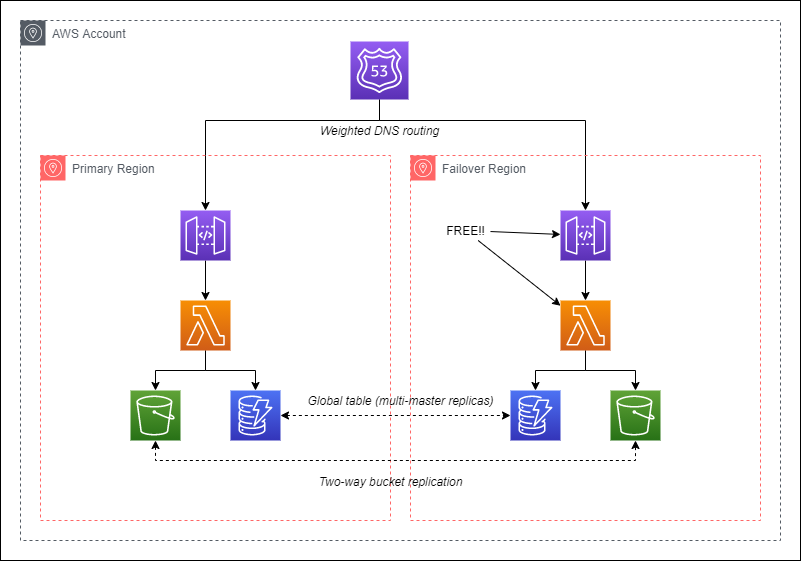
Fully replicated serverless application (simplified)
Idealistically, that would be all for your additional costs to have a multi-region failover. Pragmatically, these likely aren’t the only additional costs you will encounter.
Chances are your application runs some sort provisioned resource. Be it some EC2 instance to run batch jobs or OpenSearch for advanced searching capabilities, there are few applications out there that are 100% serverless. To run an active-active failover, you must have these provisioned resources on and running in both regions. Which means your provisioned costs will double.
With EC2 you could run an active-passive strategy that requires you to spin up your instances on demand. But with OpenSearch, domains cannot be turned off. So you would need to run it active. This can result in some costly AWS bills.
Is It Worth It?
Determining if a cross-region failover strategy is worth it results in the most common answer you see in software development: it depends.
Do you have a mission-critical workload that cannot be interrupted or an SLA with a 99.999% uptime requirement? You might need a cross-region failover. Availability can be a significant driver in your decision to pursue your own failover mechanism outside of what serverless provides built-in.
In the extremely rare event that AWS has a region-wide outage that affects your application, do you think you can run the failover playbook to shift to the other region by the time AWS fixes the outage? Is it worth the risk?
With serverless, you already have extremely high availability and very low RPO with your data. That’s one of the benefits of going with the architecture. But you have to consider all the components in your system. Chances are you have some other resources that might be affected as well that are not serverless. What do you do with them?
In the AWS Well-Architected Framework, disaster recovery has its own section in the Reliability Pillar. It talks about many of the things we’ve talked about today.
However, in the Serverless lens of the Well-Architected Framework, it focuses much more on recovering from misconfigurations and transient network issues. It also recommends using Step Functions to provide ways to automatically retry failures and observe your system. In some cases, using Step Functions is also a cost saver over Lambda.
Reading between the lines, this could mean that traditional disaster recovery might not be as important as years past. That is part of the reason we went with serverless, after all.
Conclusion
You should always plan for when something goes wrong. In some cases, wait it out might be a perfectly viable plan. If there is no way you can failover or recover in the time it would take your cloud vendor to recover, then you might be wasting your time.
For some workloads, you don’t have that luxury. Implementing measures to do cross-region replication like DynamoDB global tables and S3 cross-region replication are a must because of your availability needs.
If your application runs mostly serverless, it’s probably worth the extra few dollars a month to increase your reliability. If you have a hefty workload on provisioned services like OpenSearch or EC2, you might want to weigh your options for cross-region.
You already have multi-availability zone redundancy with serverless. You are covered in many use cases. But it’s always a good practice to play the “what if” game and make sure you know what to do.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.