Serverless

Building Serverless Applications That Scale The Perfect Amount
One of the benefits you’ll hear when people pitch you on serverless is that “it handles scaling for you and you never have to worry about it.”
Man I wish that was true.
It’s not.
What is true, is that your cloud vendor does handle the scaling events for you. Pretty well, too. It’s handled without any interaction from you and it scales to virtually any level (assuming you have increased service quotas).
What is not true is the fact that you don’t have to worry about it. You absolutely have to worry about scale when designing serverless applications.
When designing your application, you need to know roughly the degree at which requests will be coming in. Is it 1 request per second? 10? 1,000? 100,000?
For each order of magnitude you scale you need to consider how you’ll handle the increased load across the system. Scale doesn’t just refer to how your API Gateway handles traffic. It’s how your database, back-end processes, and APIs handle traffic. If one or more of those components don’t scale to the capacity as everything else, you’ll run into bottlenecking and decreased app performance.
Today we’re going to talk about different ways to build your application based on the expected amount of scale (plus a little extra, for safety).
Disclaimer - There are no industry standard names or definitions for various scale levels. The names I will be using are made up and not intended to reflect on the quality or meaningfulness of the software.
Small Scale (1-999 requests per second)
When operating a system at a small scale, you’re in luck. You can build without too many special design considerations. In theory, things should just work. Now that doesn’t mean take the first example project you see and ship it (you should never use POC’s in production, anyway).
But it does mean that in most situations you can design your application to follow the standard patterns for serverless architectures.
At small scale, the basic serverless building blocks are your best friends and will get you far. But no matter what level of scale you plan for, you must remember to check the service quotas for the services you will be consuming. Consider the following pattern for an API at a small scale.
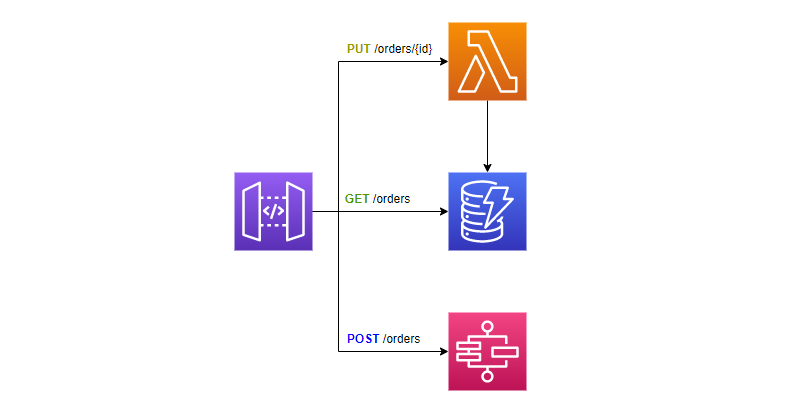
API structure for small scale
The service quotas that you care about with this architecture are:
- Lambda function concurrent executions - default 1,000
- Capacity unit size for DynamoDB
- Start execution limit for standard workflow state machines - default 1,300 per second for some regions, 800 per second for others
There are other service quotas for the services this architecture consumes, but at this scale we will not hit them.
If we reach the top of our scale and/or our average Lambda function execution time is longer than a second, it would be a good exercise to request a service quota increase on concurrent executions. If your average execution time is very low, around <200ms, you might be in the clear as well.
If you start hitting 70-80% of your service quota regularly, you should request an increase.
For DynamoDB, you have a couple of options. You could provision capacity which sets the number of reads and writes per second for your service or you could use on-demand mode which scales for you if you have variable or unknown workloads.
If you use on-demand capacity, you do not have worry about scaling. DynamoDB will scale automatically for you. But if you are using provisioned capacity, you need to make sure you’ve honed in on the amount of throughput you really need.
With Step Functions, you need to be cautious about how many standard workflows you’re starting via your API. The default number of standard workflows you can start is 1,300 per second with an additional 500 burst in us-east-1, us-west-1, and eu-west-1. If your application operates outside of those region, you’re limited to 800 by default.
Note that this service quota is for starting new executions. You can have up to 1 million executions running concurrently before you start getting throttled. But at this scale, we probably don’t have to worry about that.
Medium Scale (1,000-9,999 requests per second)
The next level of scale definitely needs some design considerations. If you expect a consistent load of 1K - 10K requests per second, you need to factor in a considerable amount of fault tolerance. At this scale, if 99.9% of your requests are successful, that means you’re looking at 86,400 to 864,000 failures a day. So fault-tolerance and redundancy have a special place at this level of scale.
While you should always design for retry, it becomes especially important when you’re talking about scale. Managing retries and fault tolerance at this scale quickly becomes an impossible task for humans to do, so automating the process is a key part of your success here.
Let’s see how our architecture diagram updates when we move to medium scale.
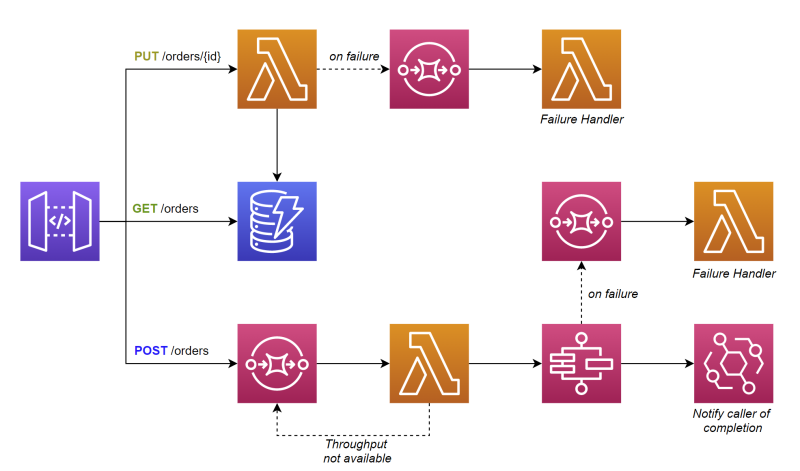
API structure for medium scale
The architecture has been modified slightly. We still have endpoints that connect to Lambda and DynamoDB, but we no longer connect to Step Functions directly. Instead, we put an SQS queue in front of it to act as a buffer. This inadvertently makes the endpoint asynchronous.
A Lambda function pulls batches from the queue, verifies Step Function throughput is available, and starts execution. If it is not available, it will put it back on the queue to backoff and retry.
When the state machine has completed, it fires an EventBridge event to notify the caller the operation is complete.
With this architecture and level of scale, the service quotas you should care about are:
- Lambda function concurrent executions - you must request an increase to accommodate the throughput
- EventBridge PutEvents limit - defaults to 10K per second for some regions, but as low as 600 per second in other regions
According to the documentation, Lambda function concurrency can be increased to tens of thousands, so we’re covered here and we don’t have to worry about the additional “Lambda function glue” we’ve added between SQS and Step Functions.
With the new influx of Lambda functions in this design, we need to implement reserved concurrency on lower priority functions. Reserved concurrency takes part of the total Lambda function concurrency in your account and dedicates it to that function. The function will only be allowed to scale up to the value you set. This prevents a low priority function from running away with all your concurrency unnecessarily. Using reserved concurrency still allows functions to scale to 0 when not in use.
On the flip side of reserved concurrency, provisioned concurrency keeps N number of function containers hot, so you don’t have to wait for cold start times. This is particularly important for getting response times as low as possible.
This would also be a good time to talk about DynamoDB single table design and how your data model is especially important at this scale. With single table design, all your data entities live in the same table and are separated out logically through various partition keys. This allows for quick and easy access to data with minimal latency in your service.
But DynamoDB has a limit of 3,000 read capacity units (RCU) and 1,000 write capacity units (WCU) per partition.
If your data model does not distribute requests evenly, you’ll create a hot partition and throttle your database calls. At medium scale or higher, the way your data is saved is crucial to the scalability. So be sure to design the data model in a way that enables easy write sharding so your data partitions are diverse.
Lots to consider when we reach the second tier of scale. But there’s even more to account for when we reach the final level of scale.
Large Scale (10,000+ requests per second)
Justin Pirtle gave a talk at AWS re:Invent 2021 about architecting your serverless applications for hyperscale. In his video he talks about best practices for applications that reach large scale use. The most important factors? Caching, batching, and queueing.
With these factors in mind, let’s take a look at how our architecture changes from the small scale model.
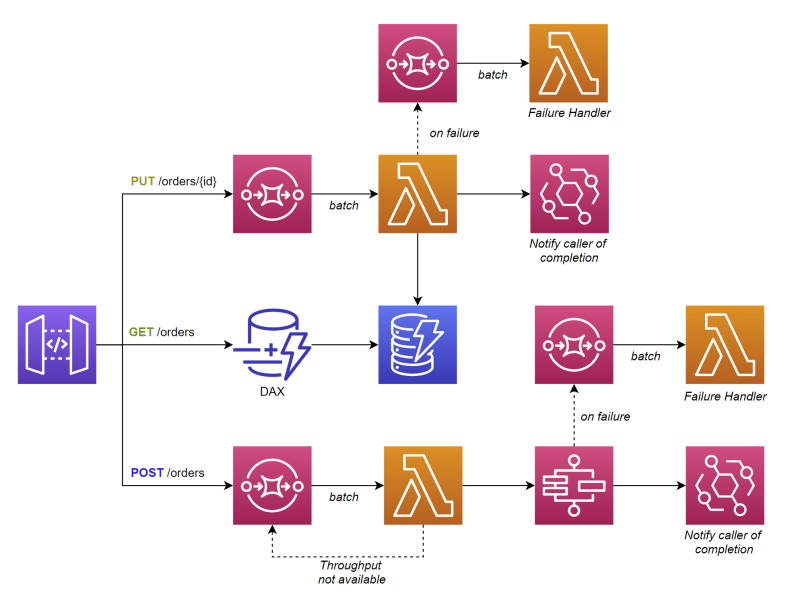
API structure for large scale
With an architecture like this, we rely heavily on asynchronous processing. Since almost all of our API calls are resulting in queueing, that means most calls are going to rely on background batch processing. API Gateway directly connects to SQS, which results in a Lambda function pulling batches of requests for processing.
When processing completes, it fires an event to notify the caller processing has completed. Alternatively, you could follow a job model approach to let the caller query for a status update themselves.
If an error occurs processing one or more items in the batch, you can set the BisectBatchOnFunctionError property on your event source mapping to split the batch and retry. This allows you to get as many successful items through as possible.
We’ve also introduced the DynamoDB Accelerator (DAX) in front of our table to act as a cache. This helps keep the RCUs down on our table and also provide microsecond latencies for cache hits.
All the service quotas from the previous levels of scale still apply at this level, plus a couple extra:
- API Gateway requests per second - defaults to 10K per second across all APIs per region
- Step Functions standard workflow state transitions - 5K per second in some regions, 800 per second in others
At large scale, your architecture concerns begin to get higher level as well. Since there are so many service quotas that must be managed and increased, it is a good idea to separate your microservices into their own AWS accounts. Isolating services to their own accounts will prevent unnecessary resource contention. You’ll have more accounts to manage, but your service quotas become considerably easier to hit.
API Gateway has a soft limit service quota for the number of requests per second it can consume. Defaulted at 10,000, this limit is the sum total across all your REST, HTTP, and WebSocket APIs in your account in a specific region. This is why it is good to isolate your services and APIs to their own accounts. This limit must be increased at large scale.
Step Functions have an interesting service limit of 5,000 state transitions per second across all standard execution workflows. So if you have 5,000+ standard workflows running concurrently, you will get throttled if each one of them transitions a single state every second.
If you can, switch execution to express workflows. They are meant for high-volume, event-processing workloads and scale orders of magnitude higher than standard workflows. There is no state transition limit with express workflows.
If you cannot change workflow types, then you must explicitly catch and retry throttling exceptions at every state in your state machines.
Obviously an application that scales to this amount is going to cost a significant amount of money to operate. This means you should take every opportunity you have to optimize performance in your application.
When possible, directly connect services instead of using Lambda. Switch your functions to use arm64 architectures. Batch your SDK calls whenever possible.
The little pieces add up quickly to save you some serious money on your monthly bill.
Conclusion
Size matters.
The amount of traffic your application gets directly affects how you design the architecture. Design for the scale you will have in the near future, not the scale you will have in 10 years.
Serverless is not a silver bullet. It does not solve all of our problems simply by writing our business logic in a Lambda function.
Just because serverless services can scale doesn’t mean they will scale.
As a solutions architect, it is your job to make sure all pieces of your application are designed to scale together. You don’t want the ingest component scaling significantly higher than the processing component. That will build an always-growing backlog of requests that you’ll never be able to consume. Find a balance.
Watch your service limits. Design your application for retries. Automate everything. Watch it like a hawk. No matter the scale, you need to stay on top of your application and know exactly how it is performing at any point in time. This will help you adjust accordingly (if necessary) and build optimizations that both increase performance and lower your cost.
When you feel like you’ve built an application that scales to your expected amount, throw a load test at it. Make sure it does what it’s supposed to do.
Good luck. Designing applications for high scale is a fun and unique challenge. It is just as much about the infrastructure as it is the business logic in some cases.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.