
Solutions architect

Solutions Architect Tips - How to Design Applications For Growth
A few years ago I was asked to design a standalone application. It had singular purpose and was meant to be used independently of any other application we had at my company.
So I took the set of requirements and designed an application that was just that. It had everything self-contained and, unfortunately, was tightly coupled with the pieces that made it up.
We got about 7 months into development before I heard a scary rumor. This application needed to be a part of something larger. A player in a larger ecosystem of applications. But it was just a rumor, so we continued on.
3 months later and it wasn’t a rumor anymore. We had officially decided to pivot on the direction of the application almost a year into development. Design decisions were made with assumptions that were now completely wrong. Major components of the application that should be shared with this “larger ecosystem” were tightly coupled to incredibly focused use cases.
Needless to say, we were in a bind. Our data model needed changing. We needed different isolation levels for our microservices. And we needed to loosen up a lot of the coupling between our services.
Years later, we’re still unwinding some of the tight coupling. Despite being told the initial direction, we could have designed the application a little differently up front to avoid a situation like this.
Had we followed these guidelines for architecting for growth, we could have minimized the amount of rework and had a stronger solution overall.
Growth vs Scaling
In a previous blog post, I wrote about designing applications for scale. In that post, I go over how to design an application for an increasing amount of users in your system. Over time your user base will grow and there will be more traffic incoming to your app. This is scale.
On the other side we have growth, which is the organic increase in the size, scope, and complexity of your application. As you iterate on the feature set of your app, you are helping it grow. The footprint of the app gets larger and larger, creating a naturally more complex and difficult to maintain piece of software.
To think about the two on the same spectrum, handling more traffic (scale) would be scaling up, while building a larger set of features (growth) would be scaling out.
There’s nothing wrong with growth, it’s actually a good problem to have. But you do need to take it into consideration when coming up with your design. How will you account for new major features? Is there any possibility of your application expanding into something bigger?
Incorporate some intentional growth points into your design so things can be added, iterated, and possibly removed in the future.
Architectural Considerations
When designing an application for growth, assume there are many unknown unknowns. There are going to be new features that come in the product pipeline, but you don’t know what they are. The product owners don’t even know what they are. But you need to consider them when coming up with your design. How do you do that?
Loose Coupling
A production application of any size is going to have many moving parts. Your goal as the solutions architect is to make it so each one of those moving parts is as completely independent as possible. This means the components can be iterated and deployed on their own and not rely on other microservices or components to be deployed or work properly. If one component changes, you are not required to change the “coupled” component as well.
Generally speaking, designing a system this way means your components have little to no knowledge of each other and when they must communicate, do so with APIs rather than directly invoking functions or loading from the database. This is known as loose coupling.
Loose coupling leaves the doors wide open for application growth. Since your components and microservices don’t depend on each other, you can add on and create new components without rewriting or slowing down to a crawl.
When it comes to displaying loose coupling on an architecture diagram, you can denote these relationships with a dashed line. Tightly coupled relationships (which you hopefully won’t have many of) are represented by solid lines connecting different components.
Let’s take an example. Imagine you have a podcast application composed of several services listed below.

Podcast application service diagram
- The podcast service is tightly coupled with the document management service, which stores the audio and video files for the podcast.
- The subscriber service is loosely coupled with the podcast service, where it subscribes to events and uses the API to load episode information.
- All services are tightly coupled with the auth service and shared infrastructure service, which contain the custom authentication mechanism and things like KMS keys.
Event-Driven Workflows
An event is an action that has occurred in your system. Events not only provide loose coupling, but they also offer hooks into business processes.
For example, in our podcast application, an episode-published event is published when a new episode is created. The subscriber service listens for the event and sends an email to everyone who subscribes to the podcast.
Subscribers of the event are unknown to the publisher. There can be zero, one, or many subscribers to a particular event, which is what makes event-driven workflows perfect for growth.
When the initial development is under way, you can publish events that represent important business actions even if there are no subscribers. During future development, services can subscribe to the existing event and immediately tie in their own workflows. This is known as a webhook.
Webhooks allow for the easiest growth over time. As long as services can subscribe to your events, you can indefinitely (to a point) grow your app with new loosely coupled features. Event-driven workflows are even explicitly listed as a serverless design principle by AWS.
By using webhooks and events in our podcast example, we have effectively left the door wide open for growth by exposing a hook for future development to trigger on.
If we decided to automatically push our content to hosting services like Apple podcasts and Spotify, the episode-published event already exists for us to tie into and add that feature quickly and easily.
API Heavy
A complex application will have a number of communications between services. Your events will often require additional lookups to get the full detail of an entity and multi-service validations are necessary in advanced workflows. To facilitate this while maintaining loose coupling, you make calls to APIs.
Design your applications with an emphasis on easily extendable and consumable APIs.
By building flexible and consistent APIs, you enable future development to get the exact information they need. It also creates opportunities for consumers to manipulate data as part of a new feature set.
In the example below, we have a series of cross-service actions that occur when an episode gets published in our podcast app.
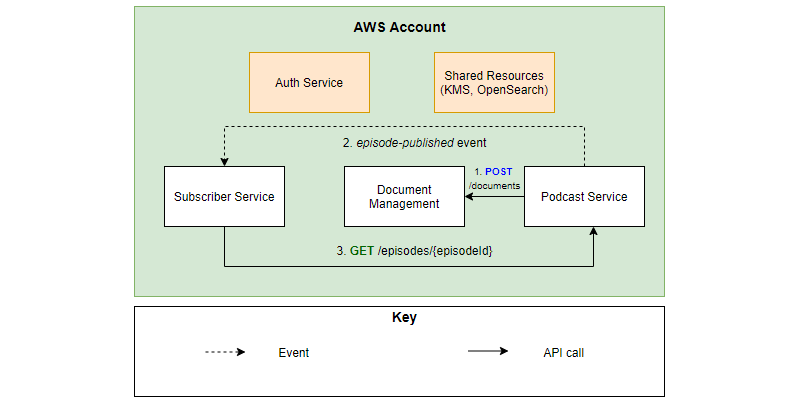
Cross-service workflow for publishing a podcast episode
- The podcast service makes an API call to the document management service to save the audio file.
- The podcast service fires an event which is subscribed to by the subscriber service.
- The subscriber service makes an API call to the podcast service to get the full details about the episode before notifying subscribers.
While designing your system to be API heavy isn’t technically architecture, it is something to consider as a solutions architect. Satisfying the workflow above is only possible because of access to a strong API.
To drive appropriate emphasis on APIs, you could push for API-first development in your organization. Putting time and energy into API design up front will make your applications easy to grow.
Conclusion
In the simple business process provided in the example above, there are two cross-service API calls and an event. As your application grows, this pattern will be repeated over and over again.
As a solutions architect, it is your job to figure out how to make components be completely separate yet work together in a seamless way. On the surface, that sounds like a daunting and borderline impossible task. But if you remember these three things, you will set yourself up for success.
- Keep your components loosely coupled so you can iterate on them independently and deploy them separately.
- Publish events on major business actions to add trigger points for future features and integrators (even if you don’t use them now).
- Build APIs for everything. If you can, keep them all public facing and build them under a common governance model.
With these in mind, you leave yourself open to growing your application to do almost anything. You don’t tie yourself down with the burden of propagating changes through a maze of tightly coupled services. You build intentional extension points with events that anything can tie into at any time. And you build easy to consume entry points into your services through APIs.
You don’t have to know the future when you build with this approach. You can get thrown curveball after curveball and your application will be able to handle it.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.