Serverless

Solutions Architect Tips - How to Design Around Serverless Service Limits
As a solutions architect, I attend project design meetings fairly regularly.
One of the things I always listen for in these meetings is the phrase “we can’t use service X because the service limit is too low”.
Believe it or not, I hear it fairly regularly.
I’m sure the obvious answer that jumps into your mind is to request a service limit increase. And while yes, that is an answer to the problem sometimes, not every quota can be increased. And if it can be increased, it might not reach the scale you need.
Service limits exist for a reason.
Before you run off and request a service limit increase, ask yourself “why does this limit exist in the first place?” AWS doesn’t want you doing that for a reason, and trying to force your way around a limit sounds like a bad idea.
Let’s take a few examples and see how we can approach the problem differently to make sure the solutions we design are using the services as intended.
SNS Filter Policies
Amazon SNS has a default limit of 100,000 topics per account (or 1,000 FIFO topics). However, you can only have 200 subscription filter policies per account.
This seems like an odd distribution. If you max out both limits, that means only .2% of your topics could have a subscription filter (assuming you had one subscription per topic).
I don’t know why the service limits vary so drastically, but it needs to be taken into consideration when designing your application.
Let’s take a real world example.
You have an multi-tenant application that allows integrators to subscribe to events. The application has an increasing amount of subscribable events as development continues.
The first time I implemented an architecture to satisfy this scenario, I was unaware of the subscription filter limit. I had come up with a plan where all subscriptions are on the same topic. A filter policy was added to each topic to include tenant, event(s), and other filters.
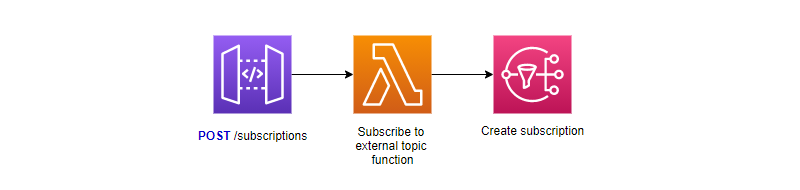
Simple approach to a generic subscribe endpoint with filters
This worked….until it didn’t. Once I reached the subscription filter service quota for SNS, I had to quickly rethink the solution.
Rather than creating a single topic that all subscriptions go through, I ended up going with many topics that were created dynamically with no filters.
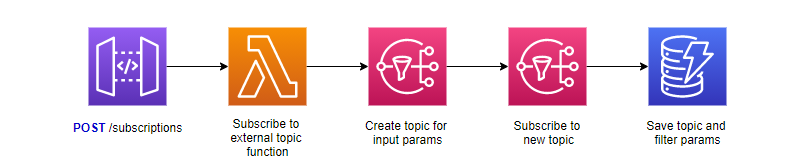
Pattern for building topics dynamically instead of using filters
This pattern allows for you to take full advantage of the vast amount of topics you can create in an account. The drawback is that you now have to manage when to publish to specific topics. This might sound like a daunting task, but it is nothing a one-to-many DynamoDB data model can’t handle.
Had I known about the service quota prior to designing this the first time, I could have saved the company some serious dev hours not needing to rework the solution.
Lambda Authorizer Result Size
Lambda Authorizers are Lambda functions that sit on top of your API Gateway to perform custom authorization. The authorizer validates the user’s identity and returns an IAM policy that includes the ARNs of the endpoints the caller can access. This policy size has a size limit of 8KB.
A while ago I pitched the idea of sharing a Lambda authorizer across your entire ecosystem. Build the auth mechanism once and have it be centralized to your application. A single call would return a policy that includes all endpoints in your application the user has access to. This was great for caching purposes, but again, we run into issues when we talk about scale.
The application I was building had dozens of microservices, with each microservice containing an API with dozens of endpoints. We were building an application that had system-defined roles, so using wildcards in the policy was not an option. Every endpoint needed to be explicitly listed in the policy.
Besides the complex burden of managing that across services for each role, it produced giant policies that eventually outgrew that 8KB limit. Once again, we had to back track and implement our solution a different way to handle the size limit.
Instead of having a single authorizer that knew about all microservices (which is a no-no, anyway), we opted to contain Lambda authorizers in each microservice. This not only reduced the size of the policy that was returned in the result, but it also enabled us more flexibility for enriching the authorizer context.
The authorizer context is enriched data, usually about the caller, that you can pass into the downstream services.
In this scenario, we thought there was no way we’d hit the 8KB limit when we initially designed the solution. But we weren’t thinking about our future selves. Always consider the scale of the not-too-distant-future in your designs. Will that scale outgrow a service quota? In my case, it did.
EventBridge Rule Targets
EventBridge routes events to various destinations via rules. The rules define what EventBridge looks for and defines the target, or destination, that is triggered by the event. Each rule has a limit of 5 targets.
I was in an architecture review meeting where someone said EventBridge was not a viable option for their project because of this limit. They thought once an event had more than 5 subscribers they could no longer use that rule.
If you have an event that needs to notify more than 5 subscribers, you’re in luck. You can use SNS to fan out to multiple targets. Just make an SNS topic one of your targets and you’re good to go.
EventBridge targets are really about distinct processes. Maybe you need to keep track of all events for auditing purposes. Or you need to transform the event and pass it along to another application. Or you simply need to notify subscribers of the event. Each one of these is a distinct process that should be its own target.

Using SNS to fan out to multiple functions
Keep in mind that limits are there for a reason. Sometimes working around a service limit in a “clever” way might get you into trouble. Use the tools as they are intended in your design. Cleverness might get the job done, but it makes your code significantly harder to maintain.
Along similar lines to the EventBridge target limit, there are best practices when working with consumers on a DynamoDB Stream. When processing streams, it is recommended that you have at most two handlers to prevent throttling.
If you have multiple processes that need to run as a result of a DynamoDB Stream, you can use the same approach as we did for the EventBridge rule targets: fan out with SNS. Either saving the content to S3 and publishing the object key in an SNS message or passing the content directly in the message will allow you to get as many consumers of the stream records as you need.
Keep in mind that the more processes running concurrently on the same data, the more careful you need to be when doing transforms.
When thinking about consumers of an asynchronous process, imagine them as distinct workflows. One consumer per isolated action. Approaching a design with the mindset of “each subscriber should be handled with infrastructure” is just asking for trouble.
DynamoDB Query Size Limits
On a lower-level note, DynamoDB has a query size limit you need to account for. When performing a scan or query operation on a DynamoDB table, the max result size it can return is 1MB. If your query matches more than 1MB of data, DynamoDB will return a LastEvaluatedKey property in the response to let you know there are more results to process.
In a previous article, I went into detail how we designed our application without this limit in mind. When entities reached a certain amount of scale in our application, data started to go “missing” in our API responses.
This is because we had not accounted for the max query size limit. The response was correctly returning a subset of data and the LastEvaluatedKey property but we were ignoring it because we had not taken that into consideration in our initial design.
To mitigate this, you have a couple of different options.
- Design your data model so queries cannot reach 1MB
- Build your application with paging in mind
When following single table design, you structure your data model in a way where you can retrieve entities and related entities with simple queries. Usually this is in the form of an overloaded composite key that combines the partition key and sort key of your entities and mutates them to represent different types of entities.
If you intentionally put effort into the design up-front, you might be able to escape the 1MB query limit.
But you can’t always design in such a way. If you must have unbounded data or your objects are exceptionally large, it will be impossible to escape this limit. So building DynamoDB paging into your app is the next best step.
You don’t want unexpected data loss, so account for the design (especially when going API-first) up front rather than in response to a critical issue.
Conclusion
Service limits are meant to act as guard rails when building your infrastructure. If your app runs into an issue with a quota on another level of scale, rethinking your design is probably the right answer. Like if you needed 10,000 SNS subscription filters instead of only 200.
In some cases, it might be better to have the quota increased, like when you need to run 1,200 concurrent Lambda functions instead of 1,000.
Whichever way you decide to go, make sure you aren’t fighting the infrastructure. Limits are there to keep you from doing something dumb. Don’t be dumb.
Designing is hard work, and knowing service quotas for all the services you consume is even harder. When coming up with your design, be sure to reference the service quota page in the AWS console to see a list of all the limits for a particular service.
Service limits are something you need to monitor for the life of your application. It’s not just a design time consideration. You need to monitor limits to make sure as you grow, you aren’t out-scaling the infrastructure. Even serverless has limits.
Most service limits can be increased, but for those that cannot - you’re stuck with a design decision. If you take a step back and ask yourself “why is it this low” you might come into a realization and understand the ecosystem a bit better.
Good luck, and I hope you keep this in consideration the next time you are building a system.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.