
Serverless

I Built a Serverless App To Cross-Post My Blogs
I do a lot of writing.
In fact, I’ve written and published a blog post every week for the last 50 weeks. It’s something that I do because I have a passion for writing and sharing the things I learn with others.
Writing not only provides me a great way to help others, but it also helps me learn by ensuring I know a topic top to bottom. It has highly benefited my writing ability, comprehension, and self-awareness. I could go on and on about it, but we’re here to talk about something else.
The hardest part about blogging is cross-posting. Cross-posting is where I take the content from my articles and post them on other websites with a link back to my blog. I republish my content on Medium, Dev.to, and Hashnode.
By cross-posting on these different platforms, I am able to reach a wider audience than if I only published content on my blog.
Unfortunately, it’s not just a simple copy/paste on these different platforms. I have to do a couple of modifications to the content that vary based on the site I’m publishing on.
- Update links - my articles often reference other articles I’ve written. On each platform I update these links to point to the cross-posted version. So all my Medium articles link to my other Medium articles, all the Dev articles point to other Dev articles, etc… This provides for a nice, unified experience for my readers.
- Update embeds - I regularly embed code or tweets in my posts. Each platform uses a different mechanism to embed content into a post.
- Set canonical url - Each post needs to point back to the original article hosted on my blog. If they do not, SEO crawlers will detect duplicate content and lower search engine rankings.
As you can imagine, this takes a good amount of time every week. Parsing through links and updating them with the right references, replacing embedded content, and setting canonical urls for three different sites adds up quickly.
So I decided to fix that. I built a serverless app that will update and cross-post my content every time I publish something new.
Let’s take a look.
How It Works
My blog is built with the static site generator Hugo and hosted in AWS Amplify. If you’re interested in how I built it, I wrote a blog post about it.
I write articles in markdown and push them to the main branch in my repository. An Amplify build is triggered, which runs Hugo to compile the markdown into HTML then it publishes the content to S3 which is fronted by CloudFront.
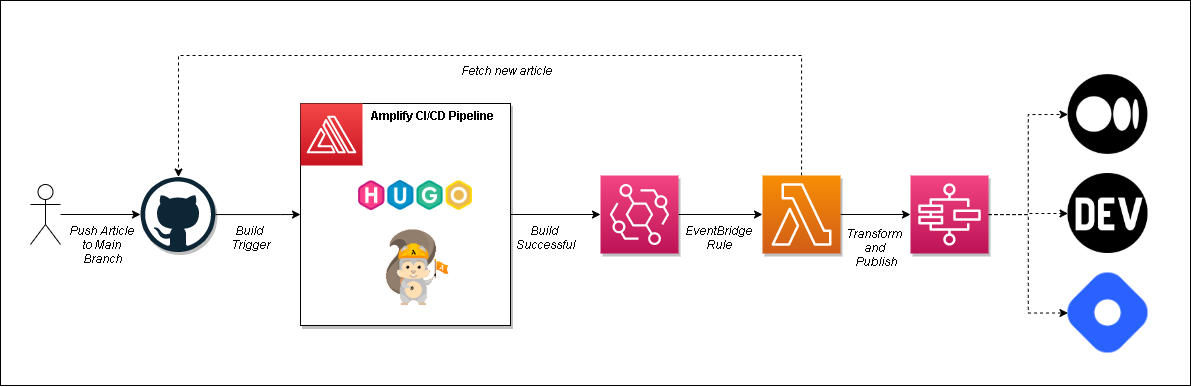
For my app, I wanted to trigger an async process to run whenever the build finished successfully. This process would fetch the file from GitHub, transform the markdown to the appropriate format, and publish it to all the different platforms.
Automation flow on a successful build
Triggering a process after a successful Amplify build was something I looked for in the docs, but couldn’t find. I was about to trigger a Lambda function directly from my build when I decided to ask Michael Liendo if he knew any tricks.
Luckily I piqued his interest. He dug deep and discovered a neat undocumented feature.
Coolness of the day - I was able to trigger a #lambda function when my @AWSAmplify build finished successfully.
— Allen Helton (@AllenHeltonDev) December 9, 2022
Shoutout to @focusotter for discovering this little tidbit. Here's the event configuration in SAM: pic.twitter.com/Ev3V4LeBop
So I was able to trigger a Lambda function with an EventBridge rule on a successful build!
This Lambda function calls into GitHub and looks for commits in the last 5 minutes that have [new post] in the commit message. It then grabs all the new files in my blog directory from the commit and starts a state machine execution that transforms and publishes the content to the various platforms.
If there are no commits with [new post] in the message or no new files in the blog directory of my repository, the Lambda function execution stops without triggering the state machine.
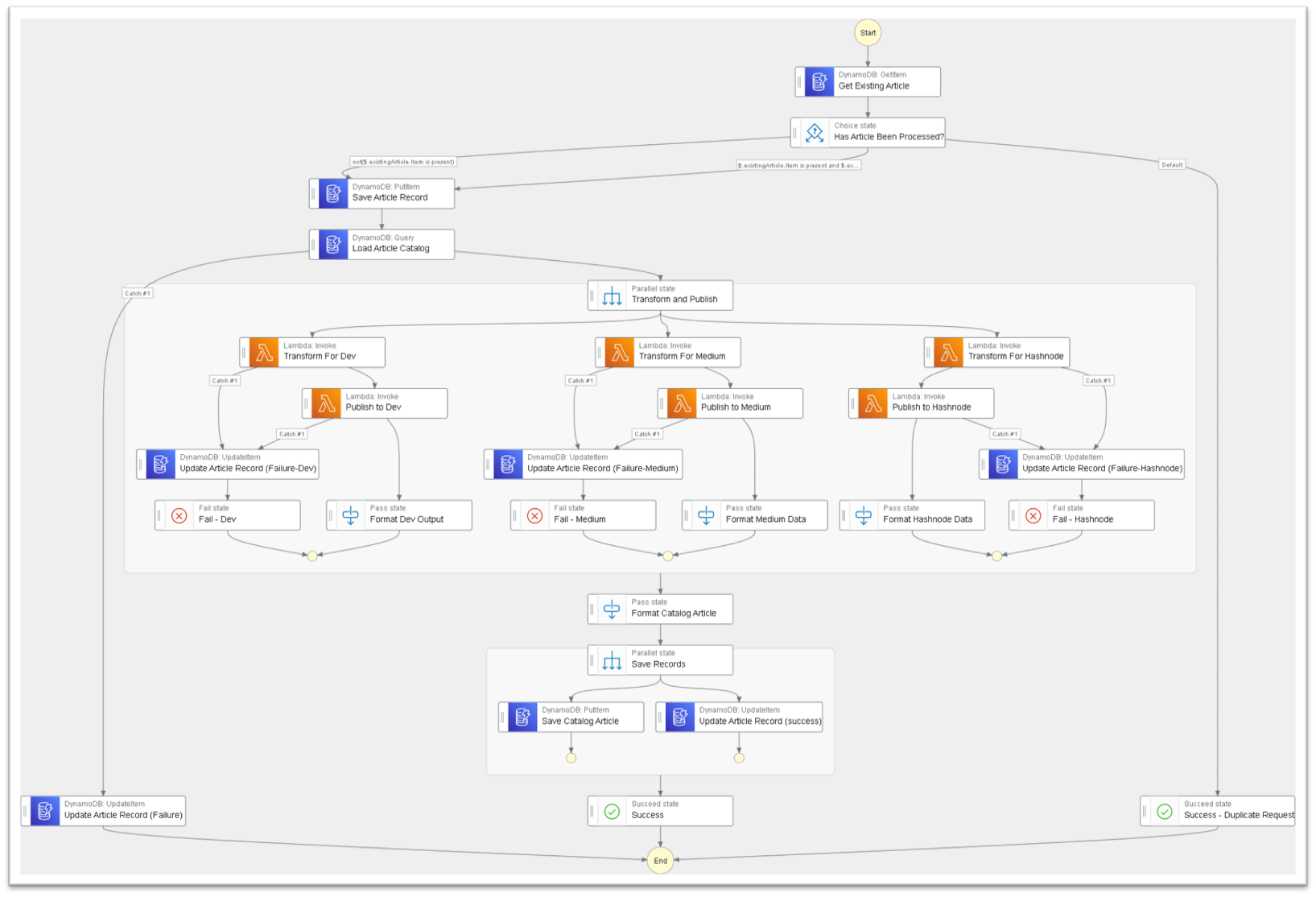
The state machine workflow looks like this:
Transform and publish state machine
To prevent the articles from accidentally being published more than once, it starts off with an idempotency check, keyed off the file name and commit sha. If multiple executions are triggered with the same file name/commit combination and the original execution is in progress or was successful, the execution aborts. If the original execution failed, it safely retries to process the article.
After the idempotency check, it uses a direct integration to DynamoDB to load all the existing articles and their mappings (more on this in a minute). Once the articles are loaded, it transforms and publishes to all three platforms in parallel.
On success, it saves the urls of the cross-posts and updates the idempotency record. Then it’s live!
Let’s take a closer look at the transform and publish components.
Updating Links
When I manually update links to point to my cross-posted versions, I have to scroll through my story list page on the platform I’m cross-posting on. I find the link to the article I referenced, then update the content accordingly.
But I can’t do that with a back-end process. It can’t “click and scroll” and find the right article.
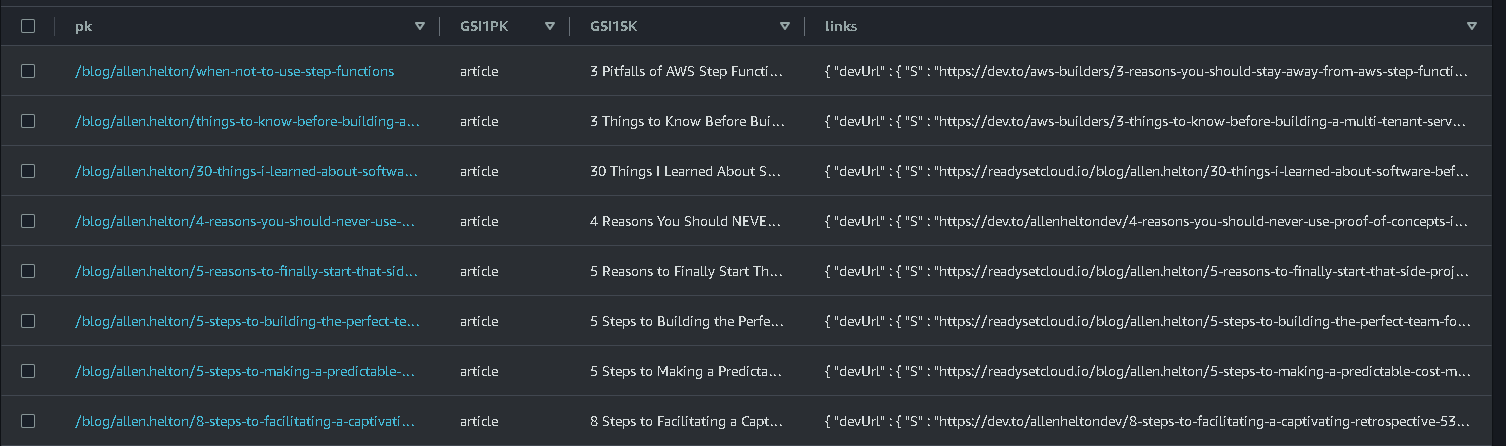
So I built a catalog of all my articles in DynamoDB.
Article catalog in DynamoDB
Each article gets a record in DynamoDB that uniquely identifies it by the post slug. The record contains a links object that contains the url to the cross-posted version on Medium, Dev, and Hashnode.
{
"pk": "/blog/allen.helton/infrastructure-from-code-benchmark",
"sk": "article",
"GSI1PK": "article",
"GSI1SK": "The Current State of Infrastructure From Code",
"links": {
"devUrl": "https://dev.to/aws-heroes/the-current-state-of-infrastructure-from-code-1fjc",
"mediumUrl": "https://betterprogramming.pub/the-current-state-of-infrastructure-from-code-cbd3469ecdc5",
"url": "/blog/allen.helton/infrastructure-from-code-benchmark",
"hashnodeUrl": "https://allenheltondev.hashnode.dev/the-current-state-of-infrastructure-from-code"
},
"title": "The Current State of Infrastructure From Code"
}
To identify links in my post, I used a regular expression to match on the markdown link format. All internal links (meaning references to other posts I’ve written) start with /blog/allen.helton/, so I was able to include that to quickly identify the links that needed to be updated.
Once I was able to grab all internal links, I simply had to iterate over them, replacing the value of my url with the mapped value in the links object of the article record.
Updating Embeds
When you see rich content in a post, that is typically the result of an embed. It’s a special piece of content presented in a way that looks more natural to readers.
The most common embed I use in my posts is for Twitter. It puts a tweet directly into the content so the reader gets the view exactly as if they were on the site. But the format of an embed is different on all the platforms I post on. For an example, here are the different structures to embed a tweet.
My Blog: {<tweet user="<username>" id="<tweet id>">}
Dev: {% twitter <url to tweet> %}
Medium: <url to tweet>
Hashnode: %[<url to tweet>]
As you can see, the structure is very different. So I had to use another regex to match on the tweet format in my blog, compose the full Twitter url, then transform it to the specific platform.
Overall not a terribly difficult part of the project, but the inconsistency was killing me!
Publishing the Articles
After the data is transformed appropriately, I use the API of the respective platform to post. This part was unexpectedly difficult. It’s also an appropriate time to talk about API-first development.
If you expect people to integrate with your software, having a strong, intuitive set of API docs is critical. If you don’t, only the really persistent integrators are going to stick with it to get their automation going. If it wasn’t for this article, I might have abandoned this project.
Of the three platforms I integrated with, only Dev had decent documentation - and even that one was iffy. The documentation states their original version of the API is deprecated, but the new version only has two endpoints implemented. I was wary to build an integration with a deprecated version, but decided to go with it. Luckily their API works very well and I had it going in just a few minutes.
Medium and Hashnode were a completely different story.
Medium had what felt like long-form writing for their documentation and hosted it in GitHub in a README. All the information I needed was there, but I had to hunt for it.
Hashnode uses GraphQL for their API and provides a testing tool with object definitions and no explanations. I had to rely on blog posts to figure out what was going on there.
But with trial and error, I was able to successfully find the right endpoints and request bodies to get my content published.
I did stray off the beaten path slightly for Medium and Dev. When I post on Dev, I always link my content to the AWS Heroes collection. Similarly on Medium, I add my content to the Better Programming publication. So I had to figure out how to submit the content directly to them to optimize the flow.
In the end, I was able to get them all working and the content linked correctly and presented in the right format.
The final part of publishing the articles is to get the post slug of the new article for each platform and create the DynamoDB entry for the story so it can be referenced in future articles.
Luckily, the full url is returned in the success response message of each of the posts, so I was able to grab them and save the data back to DynamoDB.
Final Thoughts
This was a fun little app to build that was way more involved than I originally expected. Now that it’s done’, I will be spending some time polishing and parameterizing the IaC so it can be open sourced.
Update - the source code is now open source on GitHub!
This will a huge amount of time going forward. Not only that, but it should also make my posts less prone to error. Humans make mistakes all the time. There have been plenty of times where I miss a link or forget to update an embed. With an automation, it will never be missed.
Take any chance you have to remove the human element out of a process.
If you’re reading this on Dev, Medium, or Hashnode, hopefully all the links worked for you. This post was my first production test.
I hope this post inspires you to go and build something to make your life easier. What repetitive tasks do you do that could be automated? Nowadays, there’s an API for pretty much everything we interact with - almost nothing is off the table.
If you do build something, tell me about it! I’d love to see what you made!
Happy coding!


{kind=link}
{kind=link}
{kind=link}
Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.