Serverless
 Share on:
Share on:
Skip The Lambda Function, Connect Directly To Your AWS Services
Serverless is a never ending process of constant improvement.
Improving a design. Reducing latency. Optimizing APIs for developer experience. Minimizing costs. You get the picture.
One of my favorite ways to enhance serverless systems is to reduce the amount of infrastructure supporting them.
Back in early 2021, I gave a talk at a Nimbella (now Digital Ocean) conference about power tuning your serverless APIs for happy customers. There were several optimization points in there, but the key takeaway I wanted people to remember was that API Gateway connects directly to AWS services.
When performing single operations like DynamoDB GetItem, SQS SendMessage, or Step Functions StartSyncExecution, you don’t need a Lambda function. Many of us add a Lambda function into the mix to do simple actions by default.
But you don’t need to.
The added Lambda function adds cost and complexity to your application. It’s also unnecessary code. James Beswick puts it best, “code is a liability”.
With that, let’s talk about how you can start connecting your API Gateway directly to downstream services to skip the “Lambda glue” and reduce your latency times.
Available Services
When I was doing my initial research for the services supported by API Gateway, I was expecting the “Big 6”: Lambda, DynamoDB, SNS, SQS, EventBridge, and Step Functions.
But as it turns out, there are 104 services you can integrate with directly. That’s an impressive number that opens the door to an incredible number of use cases.
In an effort to make this post readable and not 300 pages long, we won’t cover specifics of integrating with each service, but we’ll walk through one and see the components and how to extend it to whichever service you wish to integrate with.
The example we is a generic integration that should apply to most of the services in the above list.
Building the Integration
I am an advocate of API-first development. The key to success with it is defining your API via a specification document like Open API Spec. With this in mind, all of our integrations can be defined in the spec.
API Gateway has an Open API extension thats take your definition and translates it to AWS resources. It fits right into our spec as part of the path definition and is what we will use to configure the direct integration.
Directly connecting to services via API gateway mainly focuses on the transformation of the request payload to the sdk format and formatting the response into a user-friendly payload. Alex Debrie covers this stage at length in his overview of API Gateway elements.
Specifically with these direct integrations, our focus is to recreate the REST API call supported by the service. This means we must figure out the headers and request body to provide to the service.
Let’s take a real world example.
I want to build an endpoint that accepts a text string in English and returns it translated to Spanish. To do this, I can call the TranslateText API in the Amazon Translate service.
This integration would end up looking like this in our API spec.
paths:
/translations:
post:
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/translateText'
responses:
200:
$ref: '#/components/responses/ok'
x-amazon-apigateway-request-validator: Validate All
x-amazon-apigateway-integration:
credentials:
Fn::Sub: ${TranslateTextRole.Arn}
uri:
Fn::Sub: arn:${AWS::Partition}:apigateway:${AWS::Region}:translate:path/${AWS::AccountId}
httpMethod: POST
type: aws
passthroughBehavior: never
requestParameters:
integration.request.header.Content-Type: "'application/x-amz-json-1.1'"
integration.request.header.X-Amz-Target: "'AWSShineFrontendService_20170701.TranslateText'"
requestTemplates:
application/json: |
{
"SourceLanguageCode": "en",
"TargetLanguageCode": "es",
"Text": "$input.path('$.text')"
}
responses:
200:
statusCode: 200
responseTemplates:
application/json: |
{
"translatedText": "$input.path('$.TranslatedText')"
}
There’s lots to unpack with this code snippet.
First, we’ll talk about the URI. This tells API gateway which service and action it will be calling. The API Gateway documentation describes this property as:
The URI is of the form arn:aws:apigateway:{region}:{service}:path|action/{service_api}. Here, {Region} is the API Gateway region (e.g., us-east-1); {service} is the name of the integrated AWS service (e.g., s3). Action can be used for an AWS service action-based API, using an Action={name}&{p1}={v1}&p2={v2}. The ensuing {service_api} refers to a supported action {name} plus any required input parameters. Alternatively, path can be used for an AWS service path-based API.
The first thing we need to build the URI is the service name. You can get the name of a service from this gist. Just be sure to not include the .amazonaws.com piece. You only need the name. In our example, we use translate as the service name.
The next part of the URI is deciding whether or not we need path or action. Unfortunately each service is different and support varies based on which one you’re integrating with.
However, I found that if you just can’t figure out which one to use, you can model it like I have above with path/${AWS::AccountId} and provide the identifying information for the action in the X-Amz-Target header. This is a generic implementation that works on many services.
There are two headers we primarily care about:
- Content-Type of application/x-amz-json-1.1
- X-Amz-Target
Why does the Content-Type header have to be this special value instead of application/json, you ask? Unfortunately it’s not officially documented, but a solid speculation believes it is an extension that tells the AWS service additional behaviors.
The X-Amz-Target header is what tells the service which operation you want to run. This value varies based on the service you are integrating with and is not always easy to find.
The best way I’ve found to locate the X-Amz-Target value is from this AWS support ticket where it is recommend to look at the SDK docs for the service and locate the targetPrefix field in the metadata.
In our example above, the targetPrefix for Amazon Translate is AWSShineFrontendService_20170701. So we combine that with the operation we want to run, TranslateText, to build our final header value of AWSShineFrontendService_20170701.TranslateText.
The requestTemplates property above is a transformation that takes request payload and passes it along in the proper format to the service.
After the service runs, the responses property transforms the response into the format you want to return to the caller.
For more detail on these, Andres Moreno describes it beautifully in his post on how to build a serverless API in AWS without using a single Lambda function.
The final piece for building a direct integration is the IAM role. You must build a role that allows API Gateway to perform the operation you are integrating with. The role for our endpoint might look like this:
TranslateTextRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- apigateway.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: TranslateTextPolicy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- translate:TranslateText
Resource: '*'
You can see that the Principal assuming this role is scoped to API Gateway. Following the principle of least privilege, we only allow it to perform the TranslateText operation.
This role is referenced in our API spec in the credentials property of the extension.
x-amazon-apigateway-integration:
credentials:
Fn::Sub: ${TranslateTextRole.Arn}
With this, we have all the pieces to deploy our integration into the cloud! Please refer to this gist for a complete copy of the integration.
After we deploy and hit our endpoint….success!
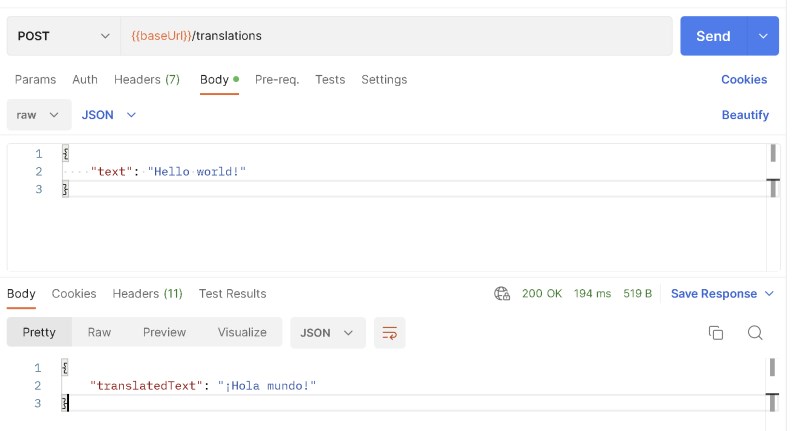
Successful integration with Amazon Translate
Not only does it work, but you can see it’s blazing fast. The round trip to do the translation was only 194ms!
Hazards of Direct Integrations
Removing a Lambda function out of the mix is a great idea in theory. It’s one less resource you need to maintain, it’s “configuration over code”, overall it’s one less piece that could go wrong.
But there are some drawbacks.
By integrating directly with a service via API Gateway, you’re losing your ability to unit test. Since no code is running, these low-level tests don’t really apply.
Some would argue that you don’t need to unit test calling a third party service. In this scenario the only thing that you could be testing is the shape of the data being passed into the AWS operation. Is that a worthwhile test, verifying your developers provide the right data to the right fields?
Instead of unit tests, you must rely further down the CI process on integration tests after your code is deployed to catch any errors.
Another important consideration is data integrity. If you are inserting data directly into DynamoDB from your API spec, you might be bypassing some important validations, enrichments, or schema checks the rest of your code is performing.
Having the shape of your entities defined in multiple places (like a shared Lambda layer and your Open API Spec integration) increases the possibility of error when your entities inevitably change. A developer could update one place but not the other, resulting in a stale format of your data.
Something that tends to cause developers to shy away from direct integrations is the use of VTL and the difficulty of the API Gateway mapping template. This is something to consider when deciding if you want to bring it into the mix with your application. Your developers and anyone who maintains your application will need to learn VTL.
There’s something to be said about upskilling your team, but some situations might lend themselves better to sticking with what you know. Especially when it comes to the complicated nature of VTL.
Summary
Integrating your API endpoints directly to AWS services is a great way to reduce latency and minimize the moving parts of your application. Simple, single operation endpoints are a good fit for this type of integration.
Unfortunately, there is no single consistent way to build them. They feel a bit like a wild goose chase at times. But the more you use them, the more familiar you will be on how to track down the right information for a given integration.
If you’re willing to take on the hazards like relying on integration tests instead of unit tests, governing the data structures strictly when using data persistence integrations, and learning VTL, direct integrations can be wonderful.
The simplicity and elegance of a direct service call is amazing. You become responsible for an IAM role and a mapping template. That’s it!
I’ve used direct integrations for a while now, but mostly with DynamoDB, SQS, and Step Functions. My team is now relatively comfortable with VTL and debugging issues related to mapping templates. For us, the decision is easy. When we can integrate directly, we will.
Costs come down, performance goes up, and fewer bugs crop up as a result of less code.
This isn’t for everyone, but for those of you who choose to go down the path of integrating with more services directly - good luck!
Happy coding!


Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.