
Application development

Build Better Serverless APIs By Going Storage First
Last week my team was having a fiery debate. They were talking about the usage of VTL exclusively for APIs.
One side of the argument debated that it enabled you to get the fastest possible response times for your API. The other side argued that it is near impossible to troubleshoot if an error occurs in your integration. The data is lost and you are forced to rely on API Gateway logs (which is a bit of a treasure hunt to set up).
Both sides make great arguments. But there has to be some middle ground somewhere. You want as low API latency as possible, but you absolutely do not want to lose any data.
Good news, there is a compromise.
Eric Johnson has been an advocate for the storage first pattern for years. Storage first refers to a set of serverless design patterns that get your data to land somewhere before running compute. That way if something goes wrong you have the ability to retry or send to a dead letter queue for manual processing in the future.
2022 is the year of async. We’re putting our focus into making faster, more reliable, idempotent APIs by embracing asynchronous architectures and patterns in our applications. By going storage first, we take a huge step in that direction.
Start With Direct Saves
Step one in a storage first pattern is to save the incoming data to a persistent location. With AWS, there are many options to choose from. You can go straight to DynamoDB, Amazon Kinesis, SQS, and even EventBridge. Each one of these services can keep a record of the incoming event so if something does go wrong, you can replay it.
Our example today is going to do a direct save to DynamoDB. The save will trigger a stream which starts a Step Function.
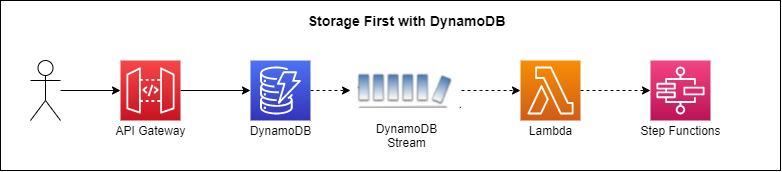 Storage first workflow with DynamoDB
Storage first workflow with DynamoDB
By going to DynamoDB, we know our data will not be lost. It goes straight to storage by proxying straight from API Gateway to Dynamo. Unfortunately this does use VTL, but just a little bit. Once HTTP APIs support integrations directly to Dynamo that will eliminate VTL completely.
By relying on the stream, we provide a buffer for ourselves. We can control the batch size, wait times, and how to handle errors through the event source mapping, which allows us to fine-tune any throttling we need for high throughput endpoints.
Process Data With Jobs
A job is an easy way to say asynchronous process. It runs in the background, does some processing, and returns a result when it completes.
This is what we want to do for our APIs. When we save directly to Dynamo, we want to save off job parameters. The DynamoDB stream will recognize a new job and send that along to Step Functions.
I’m not a fan of providing theory without practice. So I have revamped my Gopher Holes Unlimited application to show the specifics of how to setup and process jobs.
In this repo, when we add a gopher into the system, we create a job that will add the gopher, search for gopher holes at the same location, and automatically link them.
A job should represent the work that goes into creating or processing data. It is not the data itself. If I lookup details on a job, I would expect to see the job status, metadata like when the job was created, the input, and the final result (success/failure).
Our state machine that picks up new jobs must know how to handle jobs in various states for idempotency concerns. Take the following flow from the add-gopher state machine.
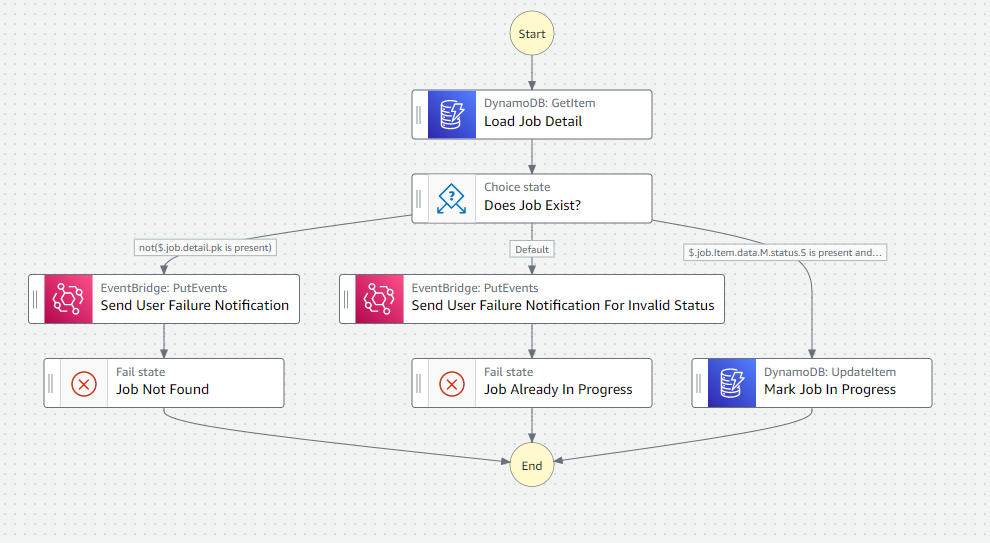 Processing a job via Step Functions direct sdk integrations
Processing a job via Step Functions direct sdk integrations
By saving our job information first, we immediately provide the ability to get the job status. We save the job details in a Pending status while we wait for the DynamoDB stream to process the new input.
The state machine is fully aware of the various job statuses and knows how to respond and update it accordingly.
Return the Right Data in Your API
By moving storage first, you are committing to returning an API response to the caller without processing their data. The only sort of validation you can run is schema validation through your Open API Spec.
Once we save the raw input as a new job, we can return a 202 Accepted status code along with the following payload to inform the caller the job was saved and to give them a way to check progress.
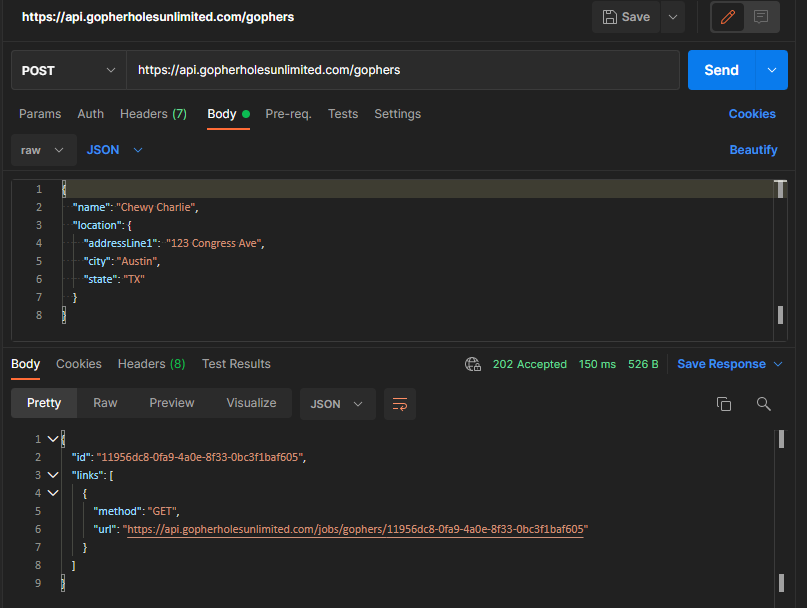 Payload and response from our storage first endpoint
Payload and response from our storage first endpoint
The response provides a job identifier which we also use as the gopher identifier. It also provides a link to an endpoint that gets us the status of our job.
Callers can use that endpoint to poll and get the status of our long running job. This is similar to how the AWS SDK works with big API calls, like the StartTextDetection and GetTextDetection commands.
If we call the link from our response, we can get immediate feedback on the status of the job we just queued.
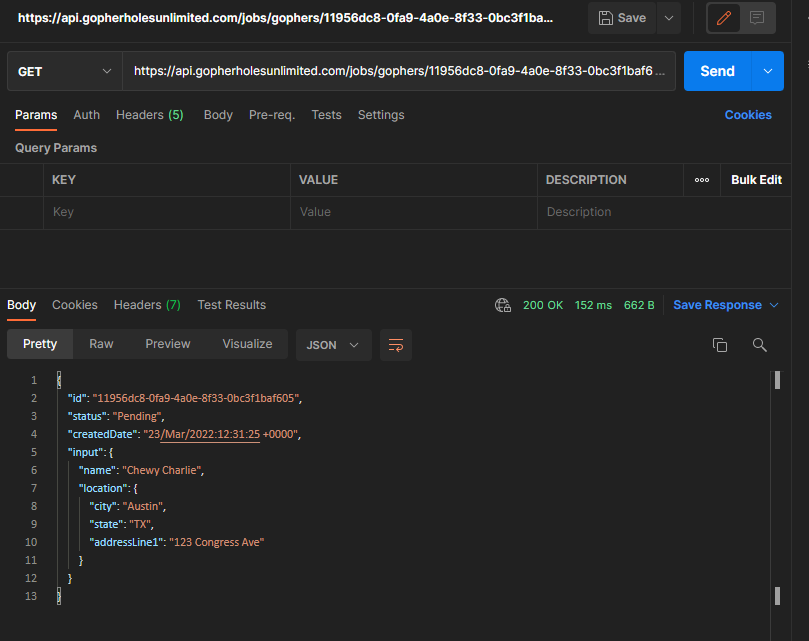 Pending status of the job we just queued
Pending status of the job we just queued
Once the job completes, end users will be able to call the GET gopher endpoint to load the details about the gopher that was created via this asynchronous process.
Give Frequent Status Updates
There are two types of status updates we need to make in this job: job status and job progress.
A job status update is a high level representation of where the job currently is in its lifecycle. These statuses include Pending, In Progress, Failed, and Succeeded. The state machine is responsible for updating the job status as it moves along its processing.
For long running jobs, it is useful to inform the user that something is going on. Nobody likes sitting and waiting hoping that work is being done. To help with this, we provide push notifications via the WebSocket microservice we created in my WebSocket tutorial.
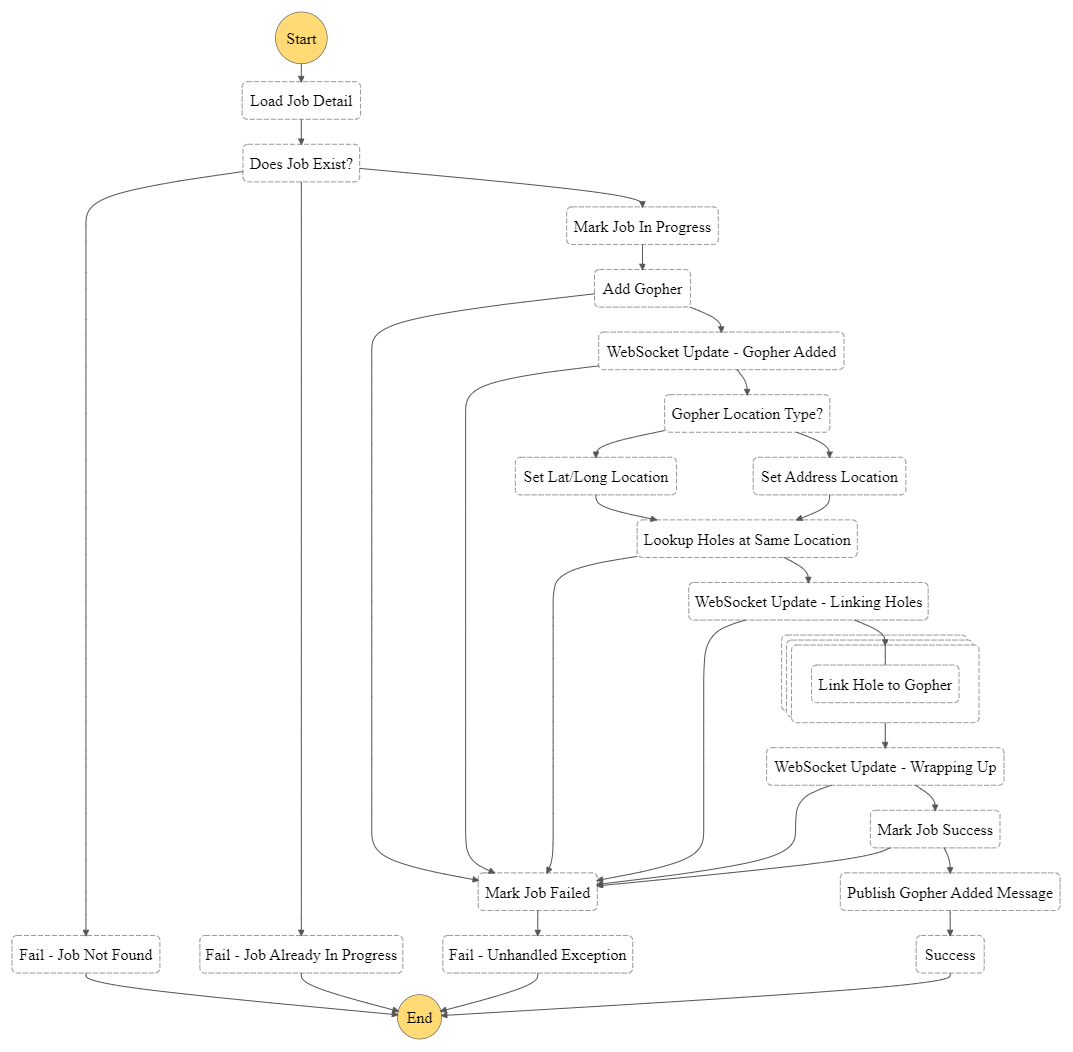 Job workflow diagram with push notifications
Job workflow diagram with push notifications
By providing push notifications, we let the user know something is happening. They can get a peek at a granular level as processes complete. All you need to do is include an EventBridge push notification in the state machine. You can see in the diagram above we send three different pushes to the user as we’re processing the add-gopher job.
Conclusion
There are several moving parts with a storage first approach to serverless APIs:
- Direct saves to a persistent storage service (like DynamoDB, SQS, EventBridge, or Kinesis)
- Job creation and workflow management
- API updates to return an Accepted status code and discovery links
- Status updates
On the surface it feels like a lot more overhead than a synchronous lambda invocation that does everything. And on the surface, that’s correct. But there are numerous benefits to going storage first and asynchronous.
- Faster response times
- User is not blocked waiting on a response
- User is notified immediately when the job is done
- Cloud costs go down because you aren’t paying for long running lambda functions
- Data traceability skyrockets since you always have a record of the data
When building production code, this is a no-brainer. If you’re building a quick and dirty POC, weigh your options. It might prove more fruitful to see it working faster than to see it working “right”.
Storage first is taking over the serverless world by storm. As we mature as a community, observability and traceability become more of a first class citizen and need to be thought about up front with your designs. Saving the data from the beginning helps make sure you never lose that rogue piece of data.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.