Level Up Your Blog With Writer Analytics and Text-to-Speech
By Allen Helton17 May 2023
I was inspired by a post from Ran Isenberg last week. He created an automation to take his blog posts, run them through Amazon Polly, and create a spoken form of his content. His automation emails him a copy of the output so he can save it on his site and enable readers to listen to the post. This is great for consumers who are in the car or have accessibility needs.
It’s a great idea and I’ve seen it a couple times recently around the community. I’m all for accessibility and love making it more convenient to consume the content I create.
I wanted to do it too.
I looked at Ran’s solution and combed through his business process, but it was quite a bit different than my workflow. So I decided to write my own implementation and add a couple of extra goodies in there.
As always, you’re welcome to follow along in the GitHub repo.
New Features
The theme of the year has been automate everything. If it can be hands-off, it will be hands-off. So I approached this build with a just do it all for me mindset. The new features include:
Post metadata - tone, sentiment, word count, writing style, and writer skill level
Automatic blog metadata updates to include all of the above
All of these things were tasks I have performed manually for years (with the exception of text-to-speech). With the soaring popularity of ChatGPT, these tasks became low-hanging fruit for automations.
Text-to-Speech
I’ll be honest. I copied Ran. And he got the idea from Jimmy Dahlqvist. Jimmy likely got the idea from somewhere like ServerlessLand. It’s not the first time this workflow has been done.
These existing implementations use Amazon Polly to convert text to spoken format and so did I. But first, I had to convert my data to text. All my posts are written in Markdown, which is great for formatting - but terrible for reading the raw format.
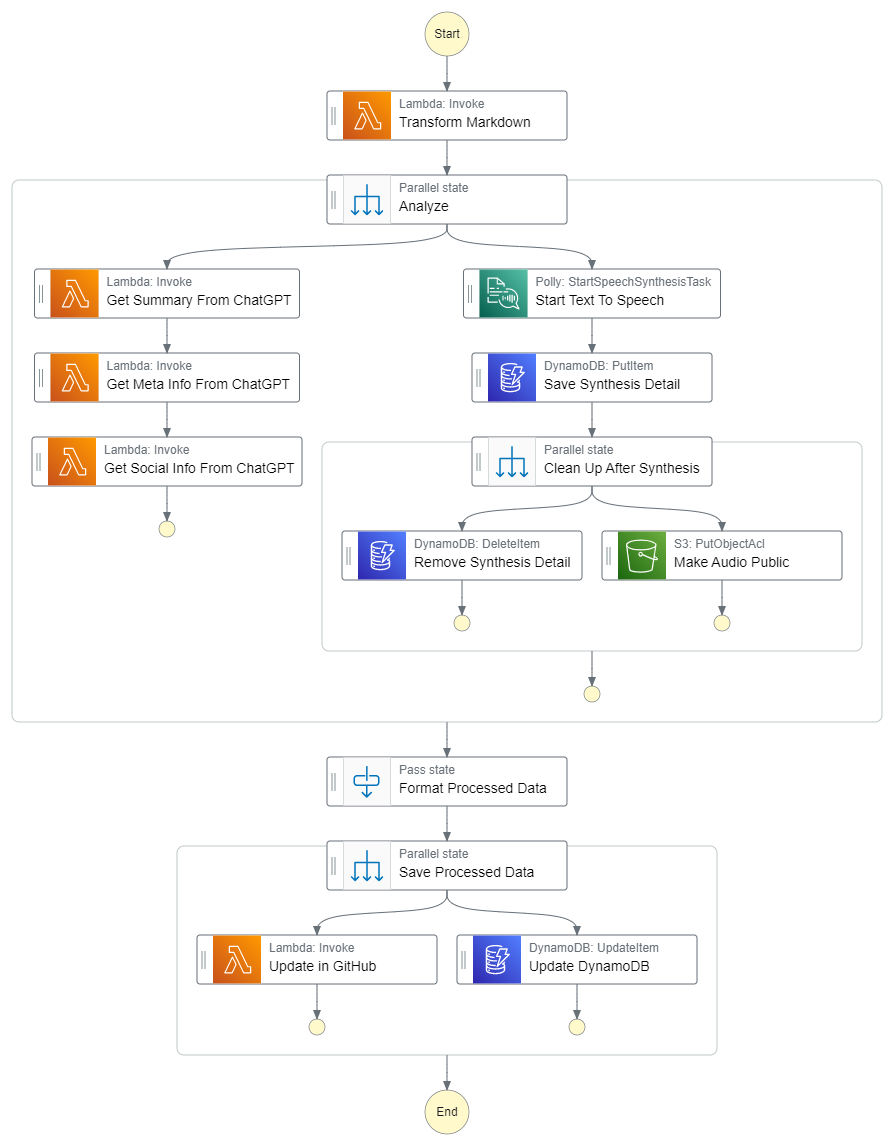
Naturally, I created a Step Function workflow to orchestrate the tasks necessary to convert the raw Markdown file to speech.
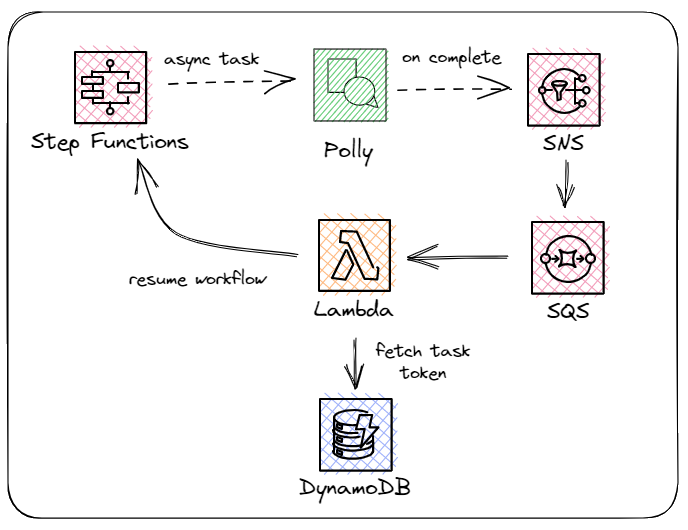
The Lambda function that kicks off the workflow takes the Markdown, parses the post metadata, converts Markdown to plain text, then returns a metadata object and the converted text. Then it starts the speech synthesis task in Polly and saves the Step Functions task token to DynamoDB.
The Step Function task token is a special token the specific execution uses to start and stop. Since I’m kicking off an asynchronous speech synthesis task, I want the workflow to wait until it’s done before continuing. To do this effectively, I save the synthesis task id and the task token to a record in DynamoDB with the following schema:
It’s a simple record that allows me to correlate the synthesis task with the specific Step Function execution. When the task completes, it fires off an SNS message that triggers a Lambda function. The Lambda function looks up the DynamoDB record via the synthesis task id, which comes in the SNS message payload, then it resumes the workflow.
Once the workflow resumes, I delete the record from DynamoDB and update the ACL of the generated mp3 to allow public read (so everyone can freely play the audio on my site).
Social Media Posts
It’s one thing to create a blog post and publish it, but it’s another thing entirely to actively promote it and make people aware it exists. Every time I create a blog post, I spend a decent amount of time composing tweets and LinkedIn posts that summarize the content meaningfully and hopefully get people to click on the link.
It’s not something I feel like I’m particularly good at, so any help in this area is always greatly appreciated. Since I already had the post content transformed to plain text and my Ask ChatGPT function from the serverless toolbox, I thought I might as well try to see what ChatGPT could come up with.
Part of the Step Function workflow runs some queries against the content of the blog post. I use ChatGPT to come up with a tweet, a LinkedIn post, and recommended subreddit and title for Reddit. To get as close to something I would write, I ask ChatGPT to write this using the same overall tone of the blog post.
I save these recommendations onto the blog post record in DynamoDB for my review. I use them as the foundation for my social media posts, tailoring them slightly if I need to.
Social Media Appearance
Awareness is everything with content creation. If people can’t find your content, then you’re just writing for yourself (which does have its own benefits, but that’s beside the point).
Have you ever noticed the cool cards that pop up when you paste a link into Twitter, Facebook, or LinkedIn? They are often eye-catching and really help drive potential readers to the content. All the data that shows up on these cards are Open Graph meta tags. Think of these as the front door to your blog post. If someone shares a link to your content, you want it to be visually appealing and encourage others to click on it, right?
Right.
That’s the next piece this new automation does for me. It takes the content of my blog post and generates an exciting, but not too “AI buzzword-y”, description for these social cards - known as an og:description. Just like with the social media posts from above, ChatGPT generates this after reading the content of the blog and summarizing it in a way that matches my tone from the article.
This does not affect SEO or even appear in search engine results. This is just the “hey, come look at me” text you see when you share the content. With generative AI doing the bulk of searches and content discovery nowadays, emphasis on SEO has faded because the algorithms are different. It’s more catered toward getting your social cards in front of real people with something eye-catching and exciting.
Writer Analysis
This is something I didn’t know I wanted until I began building it. I have a gut feeling about my writing style, but it’s good to get some assurance every so often.
I also wanted to see how my writing changes over time. I can tell you for sure I write differently now than when I started in 2019. But I couldn’t tell you exactly how. I’m pretty sure my witing skills have improved, but I couldn’t tell you how much, why, or give you anything definitive to back that up.
With that in mind, I wanted to create metrics about me. How am I doing?
Once again, I asked ChatGPT to perform this analysis. I could have used some of the AI tools provided by AWS, like the detectSentiment API from Amazon Comprehend, but tools like ChatGPT make it so easy to just add a simple “also, tell me in one word what the sentiment is” clause to a query I’m asking.
I recently discovered you can ask ChatGPT to return a json object as a response, so I updated the AskChatGPT function in the serverless toolbox to accept an outputFormat property so it could automatically parse the response as json and return it to my workflow. Now with a single call, I can ask for a json object with all the writer analytics I want to track, which results in an output like this:
{
"sentiment": "Positive",
"tone": "Informative",
"writingStyle": "Conversational with a touch of humor",
"skillLevel": 8,
"wordCount": 986
}
At this point in time, I’m just collecting this information. I am still piecing together how I want to track the trends and visualize this data. But step 1 to any sort of analysis is information gathering!
Blog Metadata Updates
I’ve written about how my blog is built a few times. It’s a static site written in Markdown that is compiled into html by the static site generator Hugo. The generated html is hosted in AWS Amplify. It’s a pretty cool and elegantly simple website (if you’re interested, I wrote a post on how I built it).
Each article has a bunch of metadata stored in the front matter like the title, description, slug, tags, etc… You can add whatever you want to this section and even use it to display custom or conditional components in your content. With this project, I had two primary motivations:
Add the location of the audio file for playback
Add the analytic data about writing style for fun
I needed to save the location of the generated audio so it can display on the page when a user is reading. The presence of the audio metadata element will conditionally make the audio player appear on the page.
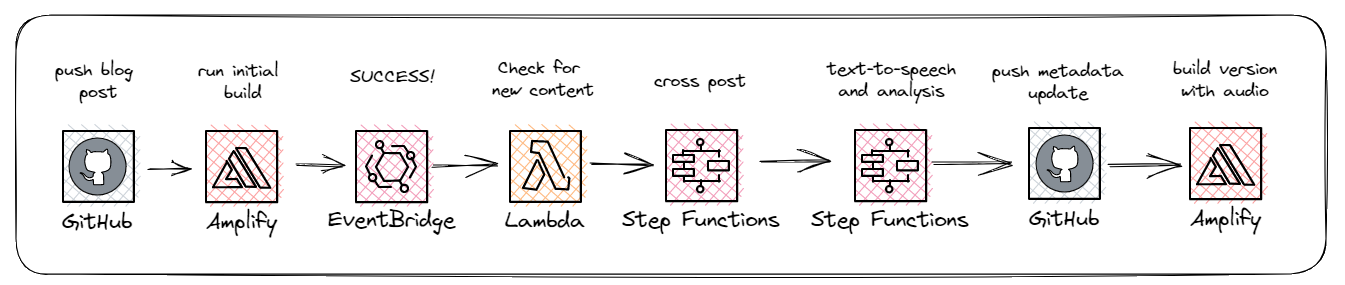
Since all my content is written in Markdown and stored in a repo in GitHub, I had to update the front matter of the specific blog post and save it back to GitHub. This would trigger another build, which would recompile my website with the audio details, enabling the audio player on the post.
So when I publish a blog post, it will ultimately trigger two builds - one for the initial publish that triggers the cross-posting to other platforms, and another to recompile the site after the audio is created and analytics are performed.
Best part? All I had to do was run that initial git push command and everything else happened automatically!
Summary
Enhancing my blog and building these automations is the most fun I’ve had programming in quite some time. Every new project is an opportunity to learn, build my skills, and share something fun with the community.
This project made me particularly excited because not only did I learn and build new skills, but I also enhanced the accessibility of my site. Bringing content to wider audience makes me happy and feel more inclusive.
I know my workflow doesn’t match everybody’s, but I do encourage you to take a look at the source code. If nothing else, it provides a notable example of using task tokens to wait for asynchronous processes to finish. It goes beyond the basic use cases for Step Functions and introduces you to some of the deeper, more powerful capabilities of my favorite AWS service.
I hope you enjoy the new functionality! I’ll continue enhancing writer analytics and sharing how that progresses. Every day it gets a little bit better and provides cooler capabilities.
If you have any questions, feel free to reach out! My DMs are always open and I am happy to help you modify the source code to get you up and running.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.