
API


Serverless API Essentials - Idempotency
When I first got into cloud development, my team and I dove headfirst into all aspects of modern software design. One of the most fun discussions we had was around idempotency.
Not because of the academic discussions we’d have around it, but because none of us knew how to pronounce it. We’d all go around the room saying it different ways and nod our heads when someone pronounced it in a way that sounded right. None of us knew what it meant, but at least it was fun to say.
When we began trying to understand what it meant and how to implement it on our serverless apps, we started disagreeing.
Idempotency (pronounced eye-dem-POE-ten-see) at its core sounds like a simple aspect of software engineering. It refers to an operation that produces the same result when called multiple times.
But it’s not that simple. There are many sides to idempotency that I recently found out not many people agree on.
I ran polls on LinkedIn and Twitter last week with a tricky idempotency question to see what the community thought. The question I posed was:
What would you do for an idempotent endpoint when a duplicate request comes in while the original is still processing?
This in itself is a very targeted question. I didn’t ask about what idempotency was or about any of the major aspects of it. But I got opinions about everything. I felt like I set a trap for rabbits but caught bears, deer, rabbits, raccoons, and vultures.
Before we dive into the details around idempotency and what is wrong or not wrong, let’s take a look at the results. I received 325 responses with a pretty interesting distribution.
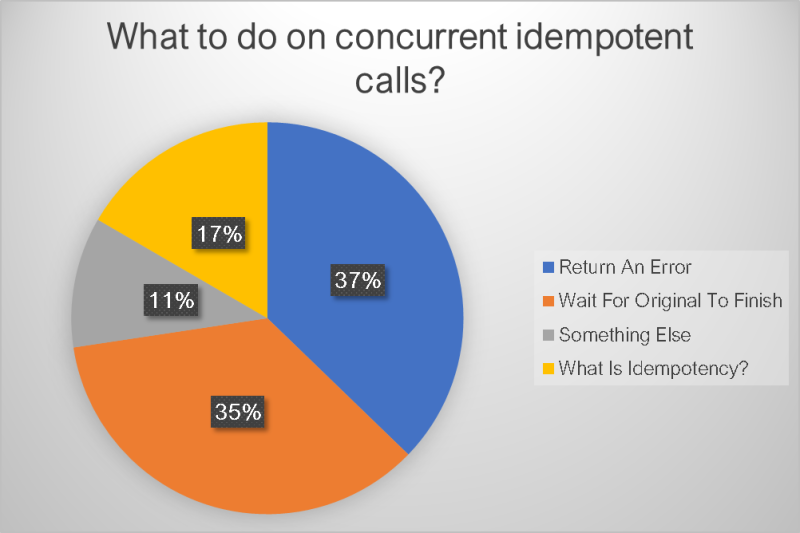
As you can see, we had a mixed bag of opinions on what to do in this scenario. This appears to be because of the ambiguity on what idempotency means in the industry. So let’s explore a bit into the various components of it.
Idempotency Principles
If idempotency was as simple as do the same thing every time you run an operation with the same payload, there would be no need for this post. Everyone would agree and it would be a strongly defined concept. But idempotency has several things to consider during your implementation, which is what makes it so hard.
Effect on the System
When we talk about idempotency, everyone can unanimously agree that idempotent calls have the same effect on the system regardless of how many times the operation is called for the same payload. But what does that actually mean? You could go a couple different ways on that one.
The operation is inherently idempotent - This means that the full operation could run with no extra considerations in design or code. A great example of this is a PUT operation. A PUT will replace all the existing values of a data entity with the content from the request. It is a strict 1 for 1 replacement that simply does an overwrite. This could be called one time or 100 times and it would result in the data entity remaining in the same state.
Some consider a DELETE operation to be idempotent as well. Calling an endpoint to delete an object multiple times will not delete the object multiple times. It will delete it one time, then perform a no-op on subsequent calls.
However, that just scratches the surface of a DELETE. If you factor in events that are triggered when a data entity is removed or audit logs that are written, does it really have the same effect as the first time it was called? Maybe on the data entity, but not on the system as a whole.
The operation must be coded for idempotency - I tend to think of this category as making sure you don’t let the caller accidentally create duplicates. The caller could be an end user consuming your API or it could be an automated mechanism performing a retry on a failed event handler.
A great example of this is handling payments. If a caller accidentally makes multiple calls to your endpoint trying to make a payment, the last thing you want to do is charge them more than once. By building your API in an idempotent manner, you can guarantee that the payment will only be processed one time.
The most common way to accomplish idempotency from a coding perspective is to accept an idempotency-key header in your requests. If your operations are asynchronous and do not have headers, you can accommodate an idempotency-key property in the payload or use something like the request id (as long as it doesn’t change on retries).
Use the idempotency-key as a lock and as a lookup key for saving the response and returning the result in subsequent calls.
Response to the Caller
This is where a lot of debate comes into play. Some people think that in order for an operation to be idempotent, the response must be identical on every call. Others believe that strict idempotency stops on the server side.
You can see the split opinions in the poll results. Those that believe the response should be the same to the caller answered “Wait for original”. The others believe that idempotency can be accomplished by returning different results depending on what the system is doing.
A good example of this is the DELETE debate. Deleting a resource will typically return a 204 No Content status code when it performs the delete successfully. But what about when you try to delete the resource again, whether on accident or on purpose? Do you still return a 204 to provide an idempotent response to the caller? Or do you return a 404 Not Found or 410 Gone status code because it doesn’t exist?
Returning a 404 or 410 status code results in the same effect on the system (excluding downstream events), so some still consider it idempotent.
For calls that use an idempotency key, we have a different approach.
When an idempotency key is used, it saves a record, locking the provided key. Once processing is complete, it saves the result to the idempotent record and unlocks the key. If another request comes in with the same key, it returns the result saved on the record.
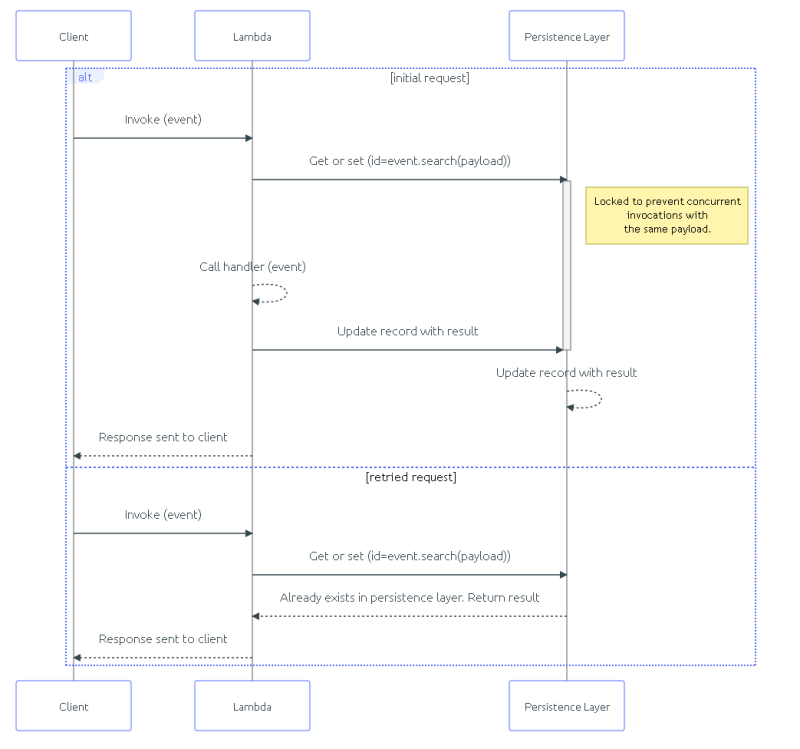
Diagram of workflow when an idempotency key is used. Source: AWS Lambda Powertools Documentation
This type of flow is where the question from my poll originated. It was asking the opinion of what you should do when a duplicate request comes in when the key is locked. Since the record is locked based on the key, the same effect will occur on the system, but what do you send back to the caller?
After reading many of the comments on the polls and having a few great conversations with Andres Moreno, Kevin Swiber, and Matthew Bonig, I’ve come to the conclusion to immediately return a success.
When I posted the poll originally, this sounded like the furthest from the correct option. It wasn’t even an option in the poll! But it makes sense. If you return a 202 Accepted status code, that indicates to the caller that an process is running on the server. You can optionally return a url to a “get status” endpoint in the response so the caller can check status themselves.
Waiting for a response is a waste of resources. You will needlessly tell your app to wait for a response just for the sake of making a call feel the same to the caller. With serverless, you’re just throwing away money forcing a Lambda function to stay alive in wait. Now that sustainability is a pillar in the Well-Architected Framework, forcing a wait would be going against AWS best practices.
A 4XX error indicates the caller did something wrong. In this case they didn’t wait long enough for processing to finish, which is not the caller’s fault. It’s also not a server side error (5XX status code). Which means throwing an error doesn’t really apply. The last thing you want is for the caller to take corrective action by changing a request or sending the request more times because they received an error.
Responses on idempotent operations differ based on the state of the original request:
- Completed successfully - The original status code and response body are pulled out of a cache, like Momento, and returned to the caller.
- Completed with a failure - The operation attempts again as if it were the original.
- In progress - Return a success and do not perform any operations.
Time To Live
As stated earlier, an idempotency key will save a record to prevent duplicates. But how long will that record live?
If you leave it forever, that means no other call will ever be able to use that key again, which may or may not be a bad thing. This brings up another good point.
You should always validate the request payload against the idempotency key.
Let’s take an example. In this reference architecture project, users can add their goats in the system so they can link goat products (soap, milk, cheese, etc..) to sell.
If two goat farmers went to add their goats in the system at the same time but used the same idempotency key, what should happen? These aren’t duplicate requests - which is what idempotency is there to solve. Instead, these are competing requests that use the same key.
In situations like this, the system should validate the request body coming in with the key and verify it matches the original request body. This is the only way to (mostly) guarantee you are preventing duplicates.
In the reference project, we take a hash of the request body and save that alongside the key. If another request comes in with the same key that doesn’t have the same hash, a 400 Bad Request is returned stating the payload does not match the original request payload.
If we never expired idempotency keys, we could run into collisions like this unnecessarily. Granted you could force the format of your idempotency key to be some sort of UUID or timestamp/hash combination, but that adds some operational overhead that might not be worth it in the long run.
So by expiring or setting a time to live on your idempotency keys, you are releasing that value back into the available pool of keys.
Remember, your objective is to prevent duplicate entries into the system, so set your time to live to be a little longer than your max retry duration. If you have a backoff and retry strategy that automatically retries a failed async process 50 times over the course of 24 hours, then set your time to live to 25 hours.
For synchronous or request/response calls, your time to live duration can be significantly shorter. The likely use case for an API endpoint sending duplicates would be an accidental double-click on a submit button. In this case the duplicates would come in immediately. For posterity’s sake, we can set the time to live on these calls to about an hour to capture any rogue requests that come in.
Record Storage
We’ve covered at length the need to track and store an idempotency record. This record has a simple key/value access pattern and needs to expire after a short period of time. It is also of utmost importance that the lookup be blazing fast to prevent duplicates in the “accidental double click” scenario or for events that were delivered multiple times.
Sounds like a great use case for caching.
Caching by definition is a high-speed data layer that stores a small set of transient data. This is exactly what we want for storing idempotency records.
Not to sound like a purist, but when I build serverless applications, I’d prefer for all of it to be serverless. Using Amazon Elasticache breaks that paradigm. That service has pay-per-hour pricing and doesn’t quite have the flexibility I’m used to when working with serverless services.
Instead, I opted for Momento, which is a completely serverless caching solution. It operates under the same pay-for-what-you-use model as AWS serverless services, including a 50GB/month free tier. Since it’s serverless, it automatically scales to match the amount of traffic and grows the size of the cache without worrying about data nodes.
Saving records to a cache instead of a database helps follow the principle of least privilege. Since we aren’t establishing a connection to DynamoDB, we can omit the GetItem, PutItem, and DeleteItem permissions from any Lambda functions that need to be idempotent because we aren’t managing the idempotency records. This locks down our functions to only the permissions needed for the operation.
Since cached data is meant to be short lived, all records will expire automatically. This behavior could be mimicked in DynamoDB by including a TTL on the record, but deleting a record with a TTL is not exact. It could expire up to 48 hours after the expiration date. By throwing records into a cache, you guarantee you won’t have any idempotency records hanging around longer than they should.
Summary
Idempotency is a big topic that results in some huge opinions in the development world. Depending on your definition of idempotent, the way you implement it could vary wildly.
That said, there does seem to be a single general consensus. No matter how you implement idempotency, duplicate calls should result in the same impact on the system.
From there we start to diverge. But I’m happy to share my opinions in an effort to make them known and hopefully start being consistent on some ideas.
- Idempotency does not guarantee an identical response back to the caller, but it is a nice bonus.
- Concurrent calls with the same idempotency key should result in a successful response and a no-op.
- The time to live on idempotency keys should be slightly longer than the total of your backoff/retry mechanism.
- Operations we consider naturally idempotent like DELETE and PUTs might not actually be. It depends on downstream actions that occur as a result of a change.
- If possible, use a caching mechanism instead of a database for idempotency records for quicker responses and on-time record expiration.
Of course we need to remember this is software, and what is the answer to most software problems? It depends. Take your use cases into consideration before implementing a solution. You might even have different strategies based on different APIs!
There are packages out there that handle idempotency exceptionally well. Serverless Python devs should strongly consider the AWS Lambda Powertools library. It handles everything we covered today, plus some extended use cases like when your Lambda function times out. Note, as of the writing of this article it is only available in Python. The TypeScript Lambda Powertools does not support it.
This post is by no means fully comprehensive and I’m sure ruffled a few feathers. Whether or not you agree with my opinions, it’s good to be aware of what others believe.
When you dive into conversations with someone on idempotency, remember to level-set first. You might not be talking about the same thing.
Happy coding!


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.